嵌入式编程杂乱笔记
嵌入式编程杂乱笔记目录
[TOC]
硬件类
NTC和PTC
NTC (Negative Temperature Coefficient 负温度系数) PTC (Positive 正温度系数)
VCC、 VDD、VEE、VSS区别
- 一、解释
VCC:C=circuit 表示电路的意思, 即接入电路的电压;
VDD:D=device 表示器件的意思, 即器件内部的工作电压;
VSS:S=series 表示公共连接的意思,通常指电路公共接地端电压;
VEE:负电压供电;
VPP:编程/擦除电压。 - 二、说明
1、对于数字电路来说,VCC是电路的供电电压,VDD是芯片的工作电压(通常Vcc>Vdd),VSS是接地点。
2、有些IC既有VDD引脚又有VCC引脚,说明这种器件自身带有电压转换功能。
3、在场效应管(或COMS器件)中,VDD为漏极,VSS为源极,VDD和VSS指的是元件引脚,而不表示供电电压。
NOR NAND
NOR(或非) NAND(与非)
SLC(Single-Level Cell)、MLC(Multi-Level Cell) 、 TLC(Triple-Level Cell)
共同点:
两者向浮栅中注入电子表示0(电子浮栅效应管存在导电沟道bit位被接地 见后续图片),未注入表示1,对其清除数据是对其写1。
- NOR FLASH
- 随机读取(可随机读取,能直接运行代码,BIOS)
- 随机读取较快、写入较很慢(热电子注入效率更低)、擦除次数较少、
- 容量较小、体积较小、可靠性高一些、数据保存期更高
- 初始通电消耗更多的电流, 待机状态电流远远更低
- 浮栅 热电子注入方式充电、FN隧道效应放电
- NAND FLASH
- 块读取(块读取,不能运行代码)
- 随机读取较慢(地址线复用导致)、顺序读取速度较快、写入较快、擦除次数较多、
- 容量较大、体积较大、可靠性较低一些(较容易发生位交换现象)、数据保存期低一些
- 待机状态功耗较高
- 浮栅 FN隧道效应充电、FN隧道效应放电
详细介绍
浮栅效应管
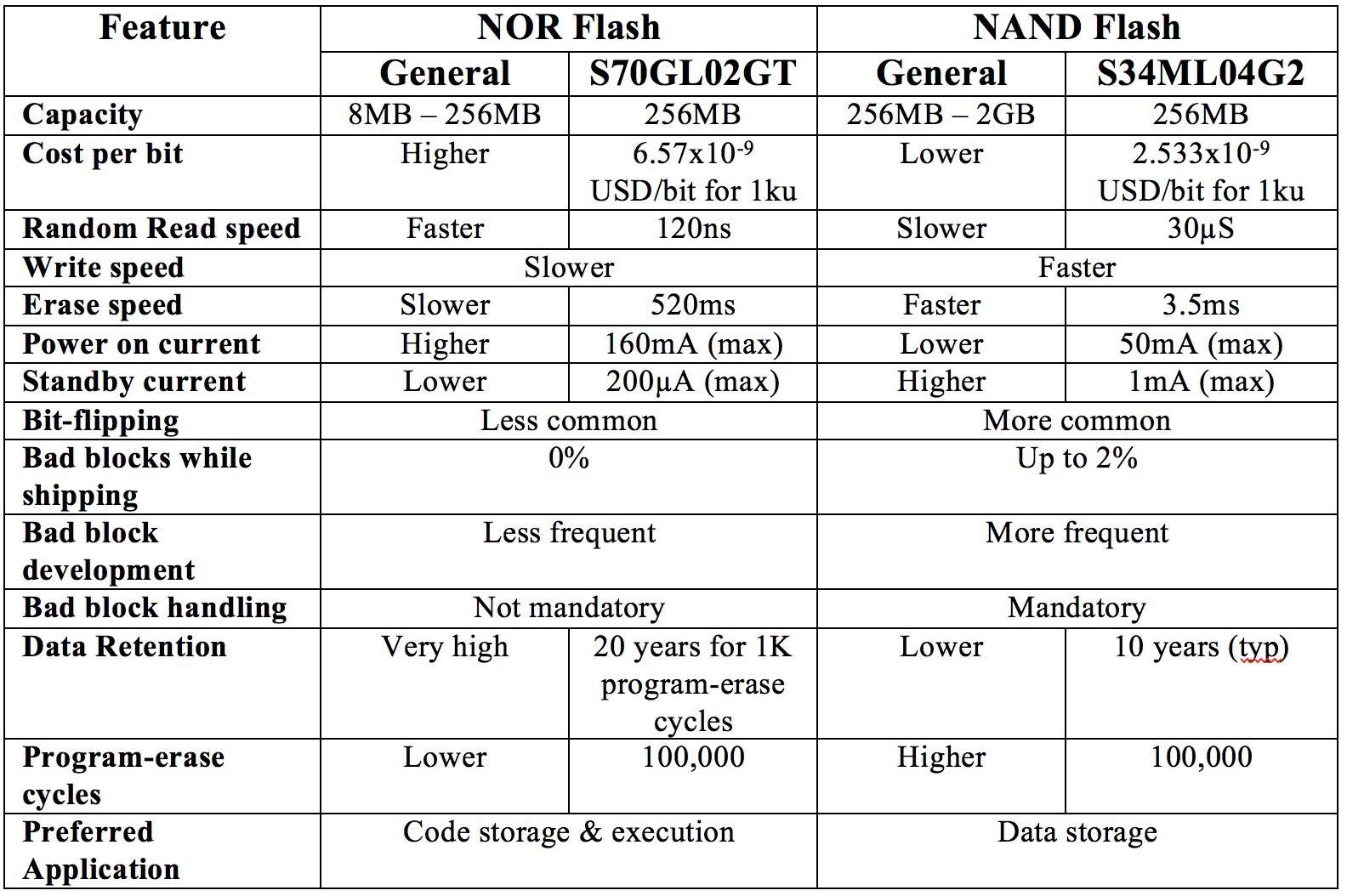
NOR FLASH 和 NAND FLASH 都是使用浮栅场效应管(Floating Gate FET)作为基本存储单元来存储数据的,浮栅场效应管共有 4 个端电极,分别是为源极(Source)、漏极(Drain)、控制栅极(Control Gate)和浮置栅极(Floating Gate),前 3 个端电极的作用于普通 MOSFET 是一样的,区别仅在于浮栅,FLASH 就是利用浮栅是否存储电荷来表征数字 0’和‘1’的。
当向浮栅注入电荷后,D 和 S 之间存在导电沟道,从 D 极读到‘0’(电子浮栅效应管存在导电沟道bit位被接地 见后续图片);当浮栅中没有电荷时,D 和 S 间没有导电沟道,从 D 极读到‘1’,原理示意图见图
注:SLC 可以简单认为是利用浮栅是否存储电荷来表征数字 0’和‘1’的,MLC 则是要利用浮栅中电荷的多少来表征‘00’,‘01’,‘10’和‘11’的,TLC 与 MLC 类似。
SLC传统上,每个储存单元内储存1个信息位,称为单阶储存单元(Single-Level Cell,SLC)。SLC闪存的优点是传输速度更快,功率消耗更低和储存单元的寿命更长,成本也就更高。一般情况下,SLC多数用于企业级的固态硬盘中,由于企业对于数据的安全性要求更高,需要保存更长时间。
MLC多阶储存单元(Multi-Level Cell,MLC)可以在每个储存单元内储存2个以上的信息位。与SLC相比,MLC成本较低,其传输速度较慢,功率消耗较高和储存单元的寿命较低。 但目前主流的固态硬盘中,性能较为优秀的产品选用的都是MLC颗粒,因此可以说MLC颗粒的固态硬盘拥有较高的性价比。甚至一些企业级的固态硬盘,使用的也是MLC颗粒,被专门优化过,称为eMLC颗粒,e代表的是企业enterprise。
TLC三阶储存单元(Triple-Level Cell, TLC),这种架构的原理与MLC类似,但可以在每个储存单元内储存3个信息位。由于存储的数据密度相对MLC和SLC更大,所以价格也就更便宜,但使用寿命和性能也就更低,不过这并不能阻止人们购买TLC颗粒的固态硬盘。甚至目前市场上绝大多数的入门级产品使用的都是TLC颗粒。而为了解决TLC颗粒过低的写入寿命问题,许多厂商都在研发新技术,3D-TLC就是这样的技术,目前已经比较广泛的应用在产品中,其性能甚至可以和MLC颗粒一较长短,使用寿命得到大幅度的延长。
读 写 擦除
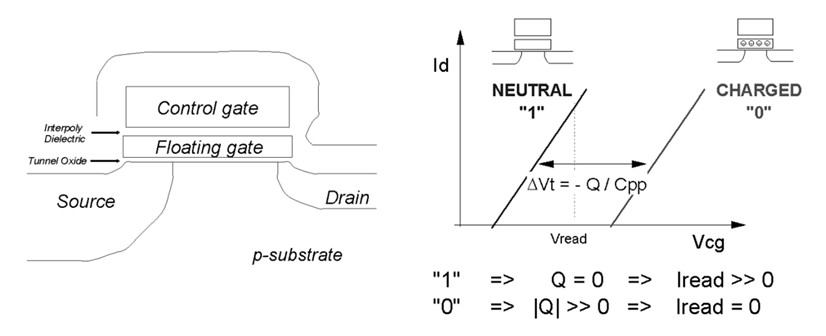
FLASH 中,常用的向浮栅注入电荷的技术有两种—热电子注入(hot electron injection)和 F-N 隧道效应(Fowler Nordheim tunneling);从浮栅中挪走电荷的技术通常使用 F-N 隧道效应(Fowler Nordheim tunneling),基本原理见图。
写操作就是向浮栅注入电荷的过程,NOR FLASH 通过热电子注入方式向浮栅注入电荷(这种方法的电荷注入效率较低,因此 NOR FLASH 的写速率较低),NAND FLASH 则通过 F-N 隧道效应向浮栅注入电荷。FLASH 在写操作之前,必须先将原来的数据擦除(即将浮栅中的电荷挪走),也即 FLASH 擦除后读出的都是‘1’。(只能擦除再写入的原因应该是擦除和写入加的电压是反向的, 一个是充电, 一个是放电)
擦除操作就是从浮栅中挪走电荷的过程,NOR FLASH 和 NAND FLASH 都是通过 F-N 隧道效应将浮栅中的电荷挪走的。
读出操作时,控制栅极上施加的电压很小,不会改变浮栅中的电荷量,即读出操作不会改变 FLASH 中原有的数据,也即浮栅有电荷时,D 和 S 间存在导电沟道,从 D 极读到‘0’(电子浮栅效应管存在导电沟道bit位被接地 见后续图片);当浮栅中没有电荷时,D 和 S 间没有导电沟道,从 D 极读到‘1’。

NOR 和 NAND Flash 的结构特性
NOR Flash
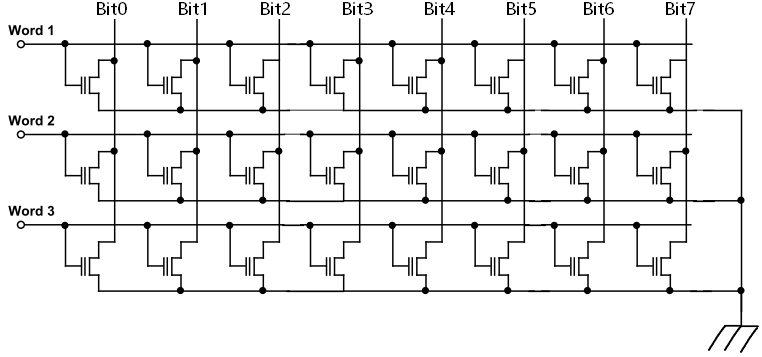
NOR FLASH 的结构原理图见图 ,可见每个 Bit Line 下的基本存储单元是并联的,当某个 Word Line 被选中后,就可以实现对该 Word 的读取,也就是可以实现位读取(即 Random Access),且具有较高的读取速率
下图是一个 3*8bit 的 NOR FLASH 的原理结构图,这种并联结构决定了 NOR FLASH 的很多特性。
下图是沿 Bit Line 切面的剖面图,展示了 NOR FLASH 的硅切面示意图,
- 基本存储单元的并联结构决定了金属导线占用很大的面积,因此 NOR FLASH 的存储密度较低,无法适用于需要大容量存储的应用场合,即适用于 code-storage,不适用于 data-storage。
- 基本存储单元的并联结构决定了 NOR FLASH 具有存储单元可独立寻址且读取效率高的特性,因此适用于 code-storage,且程序可以直接在 NOR 中运行(即具有 RAM 的特性)。
- NOR FLASH 写入采用了热电子注入方式,效率较低,因此 NOR 写入速率较低,不适用于频繁擦除/写入场合。
最后来个小贴士:NOR FLASH 的中的 N 是 NOT,含义是 Floating Gate 中有电荷时,读出‘0’,无电荷时读出‘1’,是一种‘非’的逻辑;OR 的含义是同一个 Bit Line 下的各个基本存储单元是并联的,是一种‘或’的逻辑,这就是 NOR 的由来。
NAND Flash
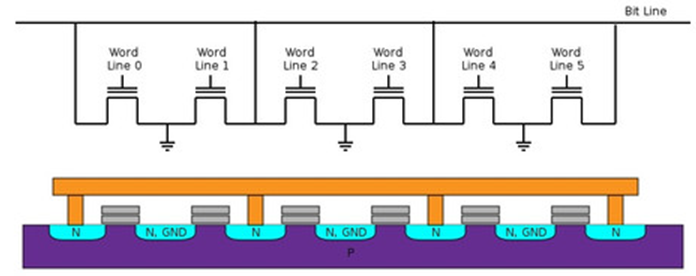
NAND FLASH 的结构原理图见图,可见每个 Bit Line 下的基本存储单元是串联的,NAND 读取数据的单位是 Page,当需要读取某个 Page 时,FLASH 控制器就不在这个 Page 的 Word Line 施加电压,而对其他所有 Page 的 Word Line 施加电压(电压值不能改变 Floating Gate 中电荷数量),让这些 Page 的所有基本存储单元的 D 和 S 导通,而我们要读取的 Page 的基本存储单元的 D 和 S 的导通/关断状态则取决于 Floating Gate 是否有电荷,有电荷时,Bit Line 读出‘0’,无电荷 Bit Line 读出‘1’,实现了 Page 数据的读出,可见 NAND 无法实现位读取(即 Random Access),程序代码也就无法在 NAND 上运行。
下图是一个 8*8bit 的 NAND FLASH 的原理结构图,NAND FLASH 的串联结构决定了其很多特点。
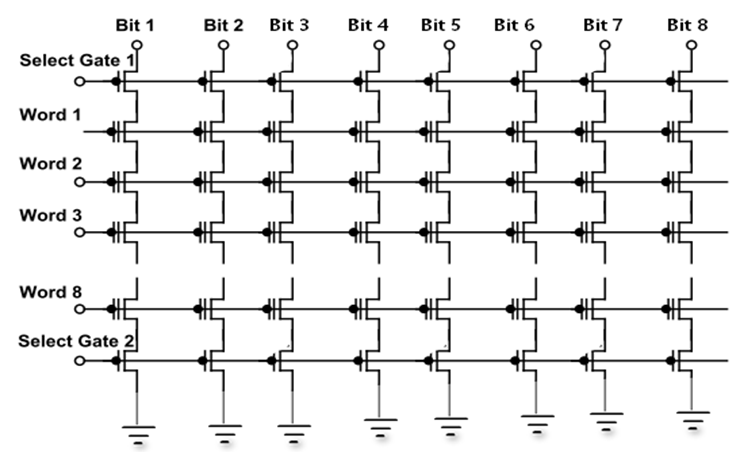
下图是沿 Bit Line 切面的剖面图,展示了 NAND FLASH 的硅切面示意图
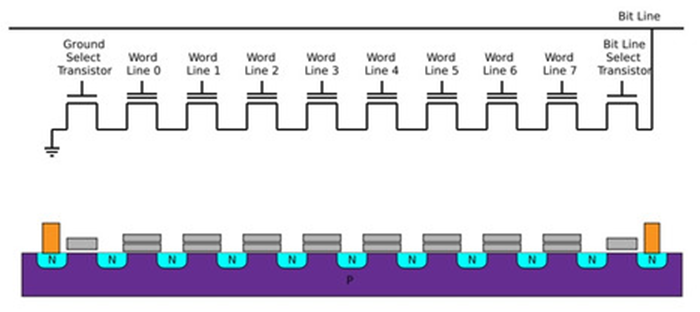
- 基本存储单元的串联结构减少了金属导线占用的面积,Die 的利用率很高,因此 NAND FLASH 存储密度高,适用于需要大容量存储的应用场合,即适用于 data-storage,见图 3.3[3]。
- 基本存储单元的串联结构决定了 NAND FLASH 无法进行位读取,也就无法实现存储单元的独立寻址,因此程序不可以直接在 NAND 中运行,因此 NAND 是以 Page 为读取单位和写入单位,以 Block 为擦除单位,见图 3.6。
- NAND FLASH 写入采用 F-N 隧道效应方式,效率较高,因此 NAND 擦除/写入速率很高,适用于频繁擦除/写入场合。同时 NAND 是以 Page 为单位进行读取的,因此读取速率也不算低(稍低于 NOR)。
最后来个小贴士:NAND FLASH 的中的 N 是 NOT,含义是 Floating Gate 中有电荷时,读出‘0’,无电荷时读出‘1’,是一种‘非’的逻辑;AND 的含义是同一个 Bit Line 下的各个基本存储单元是串联的,是一种‘与’的逻辑,这就是 NAND 的由来。
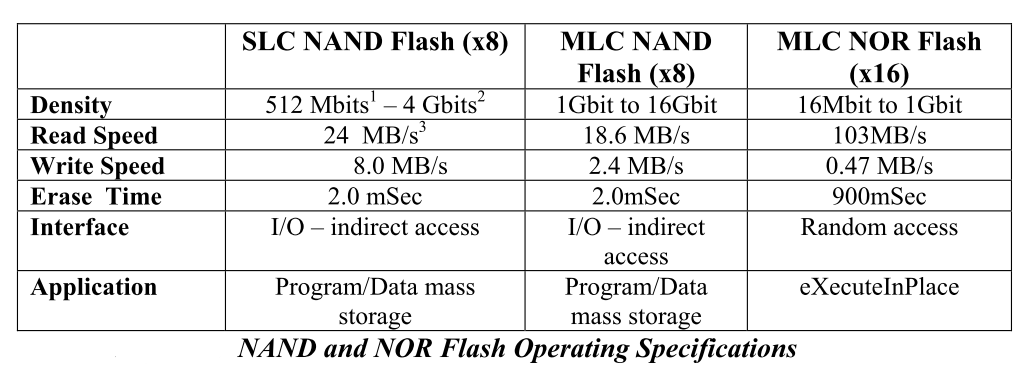
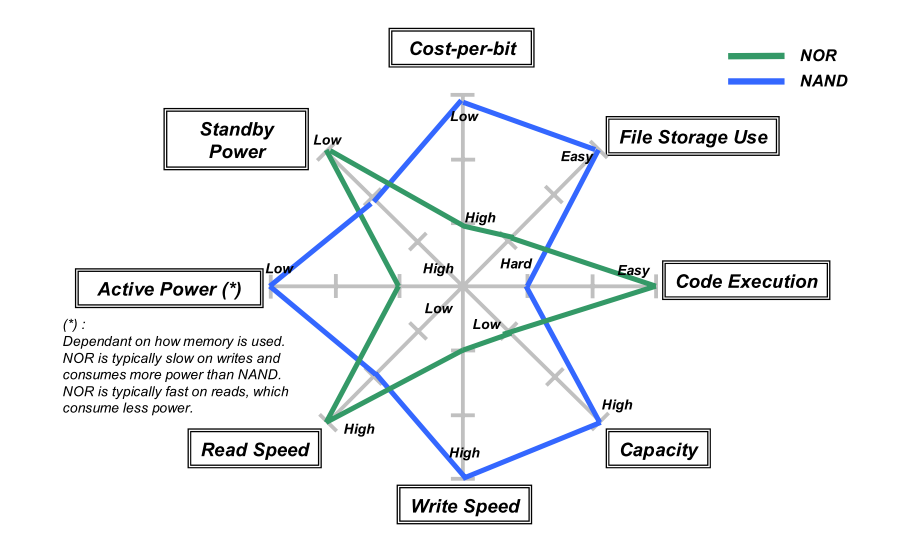
NOR 和 NAND 的对比
eMMC
eMMC (Embedded Multi Media Card) 为MMC协会所订立的主要针对手机或平板电脑等产品的内嵌式存储器标准规格。
eMMC 是 **flash(一般是NAND flash)加主控IC(坏块处理 ECC纠错 和数据管理)**,封装相对比较标准,并对外提供标准接口,类似于SD卡。
Flash的生产厂家主要有: Samsung, Toshiba,Hynix, Intel, Micron,
flash控制IC主要有:Phison(群联), SMI(慧荣), SiliconGo(硅格半导体)
几乎所有的手机和平板电脑都使用这种形式的闪存作为主存储,直到 2016 年通用闪存(UFS) 开始控制市场。
eMMC 不支持SPI-bus协议,一般使用 MLC NAND flash。
| Sequential Read(MB/s) | Sequential Write(MB/s) | Random Read(IO/s) | Random Write(IO/s) | Clock Frequency(Mhz) | Used in | |
|---|---|---|---|---|---|---|
| eMMC 4.3 | ||||||
| eMMC 4.4 | ||||||
| eMMC 4.41 | 52[11] | |||||
| eMMC 4.5 | 140[12] | 50 | 7000 | 2000 | 200 | Snapdragon 800 |
| eMMC 5.0 | 250 | 90 | 7000 | 13000 | Snapdragon 801 | |
| eMMC 5.1 | 250 | 125 | 11000 | 13000 | Snapdragon 820 |
UFS
| UFS | 1.0 | 1.1 | 2.0 | 2.1 | 2.2 | 3.0 | 3.1 | 4.0 |
|---|---|---|---|---|---|---|---|---|
| Introduced | 2011-02 | 2012-06 | 2013-09 | 2016-04 | 2020-08 | 2018-01 | 2020-01 | 2022-08 |
| Bandwidth per lane | 300 MB/s | 600 MB/s | 1450 MB/s | 2900 MB/s | ||||
| Max. number of lanes | 1 | 2 | ||||||
| Max. total bandwidth | 300 MB/s | 1200 MB/s | 2900 MB/s | 5800 MB/s | ||||
| M-PHY version | ? | ? | 3.0 | ? | 4.1 | 5.0 | ||
| UniPro version | ? | ? | 1.6 | ? | 1.8 | 2.0 |
NFC
近场通信(英语:Near-field communication,NFC),又称近距离无线通信、近距离通信,是一套通信协议,让两个电子设备(其中一个通常是移动设备,例如智能手机)在相距几厘米之内进行通信。
近场通信是一种短距高频的无线电技术,在13.56MHz频率运行于20厘米距离内[5]。其传输速度有106 Kbit/秒、212 Kbit/秒或者424 Kbit/秒三种。
NFC的工作模式有卡模式、读写器模式和点对点模式三种
RFID
射频识别(英语:Radio Frequency IDentification,缩写:RFID)是一种无线通信技术,可以通过无线电信号识别特定目标并读写相关数据,而无需识别系统与特定目标之间建立机械或者光学接触。
某些标签在识别时从识别器发出的电磁场中就可以得到能量,并不需要电池;也有标签本身拥有电源,并可以主动发出无线电波(调成无线电频率的电磁场)。
无源 RFID 标签主要在三个频率范围内运行:
NFC 与 RFID 有什么区别?
简而言之:
RFID 代表射频识别,一种在不同距离的非接触式单向通信方法。
NFC 近场通信,允许双向通信并需要用户操作,从特性上来看NFC的功能会更强,NFC是RFID的一个子集。
RFID 是使用无线电波唯一识别物品的过程,而 NFC 是 RFID 技术系列中的一个专门子集。具体来说,NFC 是高频 (HF) RFID 的一个分支,均工作在 13.56 MHz 频率。NFC 旨在成为一种安全的数据交换形式,NFC 设备既可以作为 NFC 阅读器,也可以作为 NFC 标签。这种独特的功能允许 NFC 设备进行点对点通信。
归根结底,NFC 建立在 HF RFID 的标准之上,并将其工作频率的局限性转化为近场通信的独特功能。
- 范围和应用——NFC 的作用范围非常短,一般工作范围在 0.1 米以内。它是一种用户交互技术,需要用户的特殊参与才能保证支付或访问等功能的完成。NFC技术在门禁、公共交通、移动支付等领域发挥着巨大的作用。
- 另一方面,RFID 扫描器可以同时读取大量标签,这在仓库库存中很常见。RFID 在数百英尺的距离内工作。
- 通信——RFID 通常只能进行单向通信(从标签到阅读器),而 NFC 则能够进行双向通信。
- 数据存储——NFC可以存储比简单识别信息更复杂的数据。NFC 标签最多可以存储 4KB 的数据。这些数据可以采用多种格式,包括文本、URL 和媒体。虽然 RFID 标签通常需要昂贵的读取器来提取数据,但大多数现代智能手机都配备了 NFC 读取功能。这大大降低了实施 NFC 标签的成本,因为用户可以简单地使用他们的智能手机读取数据。智能手机可以在标签或卡上读取和写入数据,获取详细的元数据,在扫描标签时启动应用程序或 URL,还可以使用 NFC(点对点 (P2P) 通信)在手机之间共享数据。
编译器相关
Keil仿真准确测量运行时间
Debug->Setting->Trsce->Core 修改好核心时钟频率即可准确测量函数运行时间
程序内存位置分配
bss段:
- 未初始化的全局变量
- BSS段(BSS segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文BlockStarted by Symbol的简称。BSS段属于静态内存分配。
data段:
- 已初始化的全局变量
- 数据段(DATA segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
text段:
- 代码段
- 代码段(CODE segment/TEXTsegment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
rodata段:
- ???
- 存放C中的字符串和#define定义的常量
heap堆:
- 堆(程序员指定的内存 malloc)
- 当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
stack栈:
- 栈
- 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
常量段:
- ???
- 常量段一般包含编译器产生的数据(与只读段包含用户定义的只读数据不同)。比如说由一个语句a=2+3编译器把2+3编译期就算出5,存成常量5在常量段中
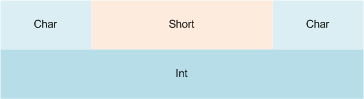
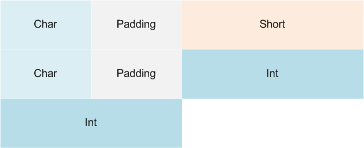
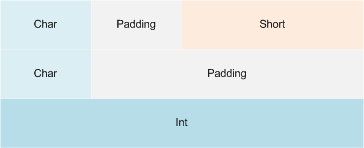
#Pragma Pack (内存对齐)
规则
复杂类型中各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个类型的地址相同
结构、联合或者类的对齐长度,按照#pragma pack 指定的对齐参数 和 这个数据成员自身长度 两个中 比较小 的那个进行。(确定成员位置)
复杂类型(如结构)整体的对齐<注意是“整体”>是按照结构体中 长度最大的数据成员 和 #pragma pack指定值之间 较小 的那个值进行;这样在成员是复杂类型时,可以最小化长度。(确定对齐大小)
即:先用规则3确定变量对齐的“容器”大小,再用规则2确定各个变量的存放位置。
看图
1 | |
- #pragma pack (1)
- #pragma pack (2)
- #pragma pack (4)
原型
pragma pack(n)
pragma pack()
1 | |
Pragma Pack(push)
Pragma Pack(pop)
1 | |
#pragma OPTIMIZE(n)(优化级别调整)
在ARM里面已经用不了
1 | |
内联函数
tip:宏函数
在大多数情况下,内联特定功能的决定最好留给编译器。使用__inline__或inline关键字限定函数的功能向编译器暗示它可以内联该函数,但最终决定权在于编译器。使用限定函数将__attribute__((always_inline))强制编译器内联函数。
__inline内联
最终决定权在于编译器,不使用
1 | |
__forceinline强制内联
__forceinline的语义与C ++inline关键字的语义完全相同。编译器将尝试内联该函数,而不管其特性如何。在某些情况下,编译器可能会选择忽略
__forceinline关键字而不是内联函数。例如:- 递归函数永远不会内联到自身中。
- 使用函数
alloca()(内存分配函数)永远不会内联。
__forceinline是存储类限定符。它不影响函数的类型。它等效于 attribute((always_inline))
1 | |
1 | |
使用递减的循环可以提高程序运行效率
- 使用简单终止循环的条件。
- 使用递减到0的循环
- 使用 unsigned int 类型
- 与0进行对比
volatile 的使用
- 访问内存映射的外围设备。
- 在多个线程之间共享全局变量。
- 在中断例程或信号处理程序中访问全局变量。
纯函数(优化)
__pure
纯函数定义:同样的的输入有同样的输出, 纯函数无法通过使用全局变量或通过指针间接读取或写入全局状态
优势:编译器通常可以执行强大的优化, 例如通用子表达式消除(CSE) 。
__packed #pragma packed 字节对齐
将整个结构声明为 __packed 通常会导致代码大小和性能的损失。
1 | |
__func__ __FUNCTION__ __FILE__ __LINE__
__func__ __FUNCTION__ __FILE__ __LINE__
获取当前函数名称
1 | |
prints:
1 | |
__attribute__((used))不能将其优化移除
用这个东西声明函数之后,即使这个函数没有被引用,编译器也不能将其优化移除,仍然要求将此函数保留在工程中。
1 | |
__attribute__((section(“XX_name”)))放置到特定的段里面
XX_name:是输入段的名称(字符串)。
这个东西是告诉编译器,将特定的函数或者变量放置到特定的段里面。
变量和函数在输入段中的地址是连续的,并顺序先按section名(也就是XX_name)排序,section内再按照函数名称进行排序。
__attribute__((at(0x00)))将变量定义到指定的地方
将变量定义到指定的地方
1 | |
__attribute__((alias(“sss”)))起别名
相当于起别名
Example
1 | |
Code RO RW ZI
Program Size: Code=14554 RO-data=1234 RW-data=272 ZI-data=6168
Program Size: Code=13682 RO-data=1098 RW-data=224 ZI-data=6160
Code
Read Only
Read Write
Zero Initial
编译器插入一个小的引导程序代码,该代码从编译好的image中获取具有初始化数据初始值的块,并将其复制到 RAM(这是 RW 区域)中。然后它将剩余的已用 RAM(ZI 区域)清零。然后控制权转移到程序员编写的实际代码中。
2
3Total RO Size (Code+Ro data) 36732 (35.87kB)
Total RW Size (RW Data + ZI Data) 27348 (26.71kB
Total ROM Size (Code + RO Data + RW Data) 36812 (35.95kB
汇编延时 不受优化影响
1 | |
大小端 endian
- 大端模式Big-endian,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
大端模式便于阅读 - 小端模式Little-endian,………..
| 0x00123456 | ||||
|---|---|---|---|---|
| 大端 | ||||
| 地址 | 0x00000000 | 0x00000001 | 0x00000002 | 0x00000003 |
| 数值 | 0x00 | 0x12 | 0x34 | 0x56 |
| 小端 | ||||
| 地址 | 0x00000000 | 0x00000001 | 0x00000002 | 0x00000003 |
| 数值 | 0x56 | 0x34 | 0x12 | 0x00 |
C类
变量命名
- 选择合适的变量长度(最短的标识符显示最多信息量的原则)
- 短变量名i,j等一般作用域较小,有限范围内有效
循环变量的命名
避免使用i、j、k等名字
如果循环体长度较长的话,那就很容易使人忘记它代表的是什么,因此最好给循环控制变量一个富有意义的名字。由于经常进行更改,扩展和拷贝等代码到另一个程序中,因此,大多数有经验的程序员都避免用i、j、k这类的名字。
通过精心对循环控制变量进行命名,可以避免它们的交叉:当你想用i时误用了j,或者想用j时却又误用了i。
如果不得不使用它们的话,那除了把它们用作循环控制变量之外,最好不再用作别的变量名。这一约定是众所周知的,如果不遵守它只会引起别人的困惑。
状态变量的命名
利用枚举类型和命名常量来设置状态量的值
如果没有注释,将数值赋给状态量将是非常费解的。
逻辑变量命名
使用肯定的逻辑变量名。
否定式的变量名如NotFound、NotDone和Notsuccessful等在“非”运算中是很难读懂的,如:
1 | |
参量的命名
对常量来说,应该用它所代表的抽象实体而不是数值来命名。
FIVE是一个很不恰当的常量名称(不管它代表的数值是否是5.0);CYCLES_NEEDED则是个恰当的名称,CYCLES_NEEDED可以等于5.0也可以等于6.0,而Five = 6.0则是个荒唐的语句。
运算符优先级

简记
算术运算符 > 关系运算符 > 位运算符 > 逻辑运算符 > 赋值运算符
- 坑
1 | |
- !!!极注意!!! 请小心有位运算时打上括号 << 比 +- 要低
1
2
3
4u16 temp;
u8 h,l;
temp = (u16)(h<<8) + l;// 正确语法
temp = h<<8 + l;// 错误语法!!!!!
printf()
| 转换说明符 | 输出 |
|---|---|
| %a,%A | 浮点数、十六进制、p-计数法(c99) |
| %c | 一个单一的字符 |
| %d | 有符号十进制整数 |
| %f | 浮点数、十六进制数法 |
| %e,%E | e计数法,E计数法 |
| %g,%G | g自动使用%e和%f,G自动使用%E和%f |
| %i | 有符号十进制整数 |
| %o | 一个八进制数 |
| %p | 一个指针 |
| %s | 一个字符串 |
| %u | 无符号十进制整数 |
| %x,%X | 十六进制数字的无符号十六进制整数 |
| %% | 百分号 |
| 标志 | 意义 |
|---|---|
| - | 项目是左对齐的;打印在字符的最左侧开始处。 |
| + | 有符号的值显示正负号。 |
| (空格) | 带前导空格,复数会带减号符号,+会覆盖空格标志。 |
| # | %o以0开始,%x以0x开始,浮点保证打印小数点,%g防止尾随零被删 |
| 0 | 前导零填充,会忽略-符号。 |
| 修饰符 | 意义 |
|---|---|
| digit(s) | 字段宽度的最小值。 %4d |
| .digit(s) | 精度。 %5.2f |
| h | 和整数说明符一起使用。表示short int或unsigned short int %hu、%hx、%6.4hd |
| hh | 和整数说明符一起使用。表示signed char或unsigned char %hhu、%hhx、%6.4hhd |
| j | 和整数说明符一起使用。表示intmax_t或uintmax_t %jd、%8jX |
| l | 和整数说明符一起使用。long int或unsigned long int %ld、%lu |
| ll | 和整数说明符一起使用。long long int或unsigned long long int(C99) %lld、%llu |
| L | 和浮点数一起使用。表示long double %Lf、%Le |
| t | 和整数说明符一起使用。ptrdiff_t(两个指针的差,相对向量)(C99) |
| z | 和整数转换符一起使用。表示一个size_t值(sizeof的返回值)(C99) |
数值数据类型 u ul b
用于说明数据类型
u == unsigned int
l == long
ul == unsigned long
数值后面加“L”和“l”(小写的l)的意义是该数值是long型。
详细说如下:
5L 的数据类型为long int。
5.12L 的数据类型为long double。
数值后面加“U”和“u”的意义是该数值是unsigned型。
用于说明数值表示方法
| 进制↓ \ 表示方法→ | 前面加 | 示例 | |
|---|---|---|---|
| 二进制 | 0b | 0b1010 = 10 | |
| 八进制 | 0 | 012 = 10 | |
| 十进制 | u l ul | 1u (规范性) | |
| 十六进制 | 0x | 0x12 = 18 |
- 注意:在宏定义中数字应加上尾缀,避免与八进制混淆
sprintf()
写入buff的数据会连带‘\0’一起写入
在 C 里,对“字符串”的通常约定,是以
'\0'为结尾的字符串。从而在传递字符串参数的时候,只需要一个指向字符串首字符的指针。来自 C 的操作字符串的函数(sprintf,strcpy,strcat, 等等)通常都遵循这一约定,包括在写字符串的时候,会在末尾添加一个'\0'。(除非在某些情况下有特殊约定)但是,
memcpy等不是操作字符串的函数,就不会添加最后的'\0'。
snprintf()
- 所传入的值以‘\0’结尾 要得到 20 个数据需要传入参数 20+1
- 如果传入的str是
"Hello"size参数是5则 无法写入'\0',size参数是6 则可以写入'\0'
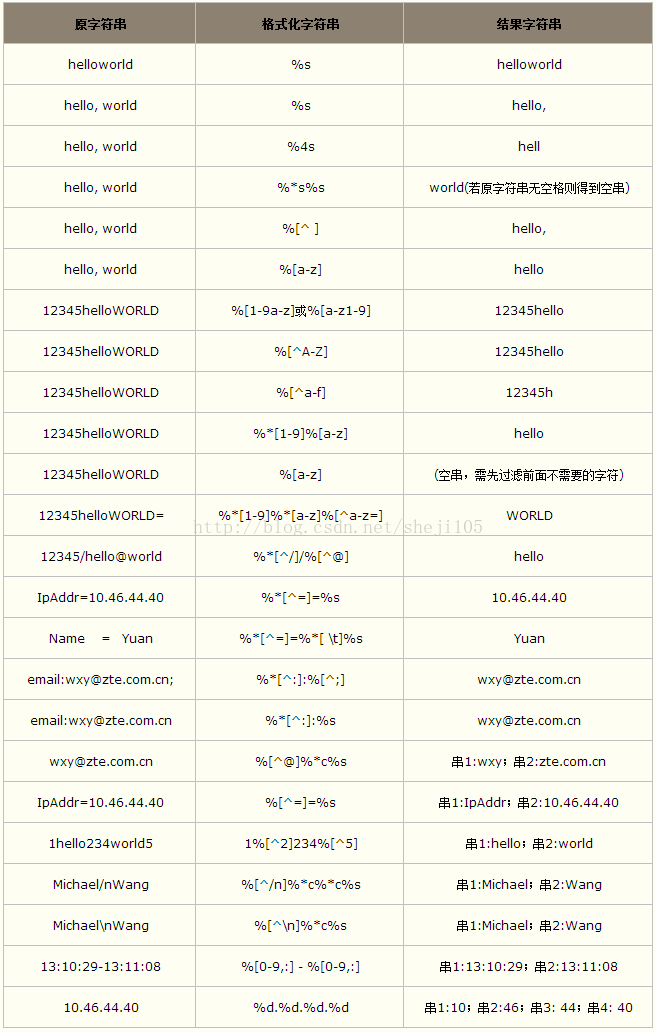
sscanf()
原型
1 | |
buffer 存储的数据
format 窗体控件字符串。 有关详细信息,请参阅”格式规范”。
argument 可选自变量
locale 要使用的区域设置
说明
sscanf与scanf类似,都是用于输入的,只是后者以键盘(stdin)为输入源,前者以固定字符串为输入源。
控制字符说明
2
3
4
5
6
7
8
9
10
11
12%c 一个单一的字符
%d 一个十进制整数
%i 一个整数
%e, %f, %g 一个浮点数
%o 一个八进制数
%s 一个字符串
%x 一个十六进制数
%p 一个指针
%n 一个等于读取字符数量的整数
%u 一个无符号整数
%[] 一个字符集
\%\% 一个精度符
函数返回值
函数将返回成功赋值的字段个数;返回值不包括已读取但未赋值的字段个数。 返回值为 0 表示没有将任何字段赋值。 如果在第一次读取之前到达字符串结尾,则返回EOF。
例程
代码
1 | |
图片
Union
数据拆分、移位
1 | |
Struct
- 注意节约内存,小数据全部写在前面方便对齐。
- 结构体内的结构体因为已经是对其了的,所以,可以建议放在最前、最后。
C语言位域的内存存放顺序
- 字节序的影响:
- 在小端字节序(如常见的x86架构)下,位域从低地址开始存储。
- 在大端字节序下,位域的存储顺序可能会有所不同。
- 编译器的实现差异:
- 不同编译器对位域的实现可能不同。例如,GCC会尽量压缩存储,而VC/VS可能不会
匿名 union struct
可以在结构体中声明某个联合体(或结构体)而不用指出它的名字,如此之后就可以像使用结构体成员一样直接使用其中联合体(或结构体)的成员。
Anonymous unions are a GNU extension, not part of any standard version of the C language.
Anonymous unions were added in C11, so they are now a standard part of the language. Presumably GCC’s
-std=c11lets you use them.
1 | |
1 | |
keil
keil也支持匿名结构体、联合体 需要使用编译器参数#pragma anon_unions
1 | |
register
这个关键字请求(只是请求,最终看编译器)编译器尽可能的将变量存在CPU内部寄存器中,而不是通过内存寻址访问,以提高效率。注意是尽可能,不是绝对。你想想,一个CPU 的寄存器也就那么几个或几十个,你要是定义了很多很多register 变量,它累死也可能不能全部把这些变量放入寄存器吧。
register是一个C语言的关键字,用来声明寄存器变量,即存放在CPU的寄存器里的变量。寄存器变量的访问速度比内存变量快得多,因为寄存器是CPU内部的组成部分,而内存是外部的设备。
- 寄存器变量只能用于基本数据类型,如int, char, float等,不能用于数组、结构体、联合等复合类型1。
- 寄存器变量的作用域和自动变量相同,即只在定义它的函数或代码块内有效1。
- 寄存器变量不能取地址,因为它们没有固定的内存位置。
- 寄存器变量的数量受到CPU寄存器的限制,如果声明过多的寄存器变量,编译器可能会忽略register关键字,将它们当作普通的自动变量处理。
volatile
- 典型用处
- 寄存器的访问
- 全局变量被中断修改
- 多线程共享的变量
- const volatile
- 两者同时修饰一个对象的典型情况,是用于驱动中访问外部设备的只读寄存器。
- (1)本程序段中不能对a作修改,任何修改都是非法的,或者至少是粗心,编译器应该报错,防止这种粗心;
- (2)另一个程序段则完全有可能修改,因此编译器最好不要做太激进的优化。
并行设备的硬件寄存器(如:状态寄存器)
延伸 const volatile
两者同时修饰一个对象的典型情况,是用于驱动中访问外部设备的只读寄存器。
- 本程序段中不能对a作修改,任何修改都是非法的,或者至少是粗心,编译器应该报错,防止这种粗心;
- 另一个程序段则完全有可能修改,因此编译器最好不要做太激进的优化。
一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
- 自动变量:是在函数内部定义和使用的变量,它是局部变量。
- 非自动变量:有两种,一种是全局变量,一种是静态变量。
多线程应用中被几个任务共享的变量
static
提高程序鲁棒性(Robust)稳健性
主要有两种用法
- 修饰全局变量也就是文件上定义的变量,防止被extern,污染命名空间(命名冲突)
- 修饰函数内定义的变量,保持变量的持久性(函数体内定义)
优化代码结构和程序性能
- 内存放在静态数据区,这样可以提高数据的局部性,提高缓存的利用效率
- 多次调用不会多次分配内存,节省内存分配时间
- 显示的声明作用域和生命周期,提高代码可读性和可维护性
默认初始化为0,不需要显式的初始化为0,存放在静态数据区(类似于全局变量的位置)
模块内不对外开放的变量都应该使用static修饰
const
- 不可变
- 提高程序鲁棒性(Robust)稳健性
- 没有修改需求的指针都应该被const修饰
关于Const指针
1 | |
Const常量可以被修改
对于一个Cont常量,实际上你访问的是它的内存拷贝,你仍然可以去用指针去修改它。
const 局部变量
const 局部变量居然定义在stack上,用指针居然可以修改其值
1 | |
const volatile
见 volatile 相关内容
指针
const 指针
有x个指针的数组
1 | |
指向x个元素数组的指针
- 指针执行
p1 = p1 + 1;操作,p1中的值会增加12个字节
1 | |
二维、多维数组的指针
1 | |
指针参数的内存传递
1 | |
编译器总是要为函数的每个参数制作临时副本,void fun_p(int *p)函数的指针参数是p,编译器为其分配的副本是_p,编译器使_p=p就是两者不是同一个变量但是指向相同的地址,函数里面修改了_P的指向,但是并没有修改p的指向,所以导致函数void fun_p(int *p)并没有得到期待的运行结果。
而void fun_p_p(int *p)函数是用指向p_a的指针修改了p_a的值。
修改某个变量,要用指向这个变量的指针!而修改指针要用(指向指针的指针)才行!
野指针 wild pointer
野指针突出一个野字,这个野就是状态未知的。它可能指向一块未知的区域。
野指针是指尚未正确初始化的指针,因此指向某个随机内存块。产生野指针是一个严重错误。
空指针
一般我们将等于0/NULL/nullptr的指针称为空指针。空指针不能被解引用,但是可以对空指针取地址。0是int类型,NULL在g++下是一个宏定义,而nullptr是有类型的;
悬空指针 dangling pointer
悬空指针是指指针指向的内容已被释放,指针指向的对象的生命周期已结束。
悬垂指针是指以前指向有效地址但现在不再指向的指针。这通常是由于该内存位置被释放并且不再可用。除非您尝试访问该指针指向的内存位置,否则悬垂指针没有任何问题。最佳做法始终是不产生或留下悬垂指针。
跳的转到指定地址执行程序
1 | |
内联函数 inline
详见Keil-> Arm Compiler 6 User’s Guides-> Inlining functions
| Inlining options, keywords, or attributes | Description |
|---|---|
__inline__ | Specify this keyword on a function definition or declaration as a hint to the compiler to favor inlining of the function. However, for each function call, the compiler still decides whether to inline the function. This is equivalent to __inline. |
__attribute__((always_inline)) | Specify this function attribute on a function definition or declaration to tell the compiler to always inline this function, with certain exceptions such as for recursive functions. This overrides the -fno-inline-functions option. |
__attribute__((noinline)) | Specify this function attribute on a function definition or declaration to tell the compiler to not inline the function. This is equivalent to __declspec(noinline). |
-fno-inline-functions | This is a compiler command-line option. Specify this option to the compiler to disable inlining. This option overrides the __inline__ hint. |
Note:
- Arm Compiler only inlines functions within the same compilation unit, unless you use Link Time Optimization. For more information, see Optimizing across modules with link time optimization in the Software Development Guide.
- C++ and C99 provide the
inlinelanguage keyword. The effect of thisinlinelanguage keyword is identical to the effect of using the__inline__compiler keyword. However, the effect in C99 mode is different from the effect in C++ or other C that does not adhere to the C99 standard. For more information, see Inline functions in the Arm Compiler Reference Guide. - Function inlining normally happens at higher optimization levels, such as
-O2, except when you specify__attribute__((always_inline)).
do while continue
1 | |
预编译ifdef
第一种
1
2
3
4
5
6
7#ifdef WIN7
xxx
#elif defined WIN8
xxx
#else
xxxx
#endif第二种
1
2
3
4
5
6
7
8#if defined(WIN7)
xxx
#elif defined(WIN8)
xxx
#else
xxxx
#endif
宏相关
一般来说在宏中不要使用增量(++i)或减量(–i)运算符。假设宏里面有多个替换,结果是不可预知的。
在宏后面对宏的注释应该要用块注释,而不应使用行注释。因为有些编译器会将行注释理解成宏的一部分(这么智障的编译器嘛??)。
define定义一个宏函数记得写 do{}while(0)
1
2
3
4
5#define device_init_wakeup(dev,val) \
device_can_wakeup(dev) = !!(val); \
device_set_wakeup_enable(dev,val);
if (n > 0) device_init_wakeup(d, v);为什么不简单写{}
1
2
3
4
5
6
7
8#define device_init_wakeup(dev,val) \
{ device_can_wakeup(dev) = !!(val); \
device_set_wakeup_enable(dev,val); }
if (n > 0)
device_init_wakeup(d, v);
else
continue;__FILE__和__LINE__,FILE展开为当前源文件的文件名,是一个字符串,LINE展开为当前代码行的行号,是一个整数。
类似上面的 C99有__func__ 可以打印出当前函数名,但是注意这是一个变量而不是宏。
gcc 定义宏
1
gcc -c -DMACHINE=8086 main.c在宏中用#将宏参量(可以是变量、函数名)转换成字符串。——创建字符串
在宏中用##将两者进行粘合变成一个标识符(变量等…)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#define X_NAME(n) x##n
#define X_CHAR(x) #x
#define PSQR(x) printf( "The square of " #x " is %d\n",((x)*(x)) )
#define PSQRx(x) printf( "The square of %s is %d\n", #x, ((x)*(x)) )
int X_NAME(1) = 5; //等价于 x1 = 5;
PSQR( x1 );
PSQRx( x1 );
printf("%s-%s-%d\r\n", X_CHAR( X_NAME(1) ), X_CHAR( x1 ), X_NAME(1) );
/*
输出:
The square of x1 is 25
The square of x1 is 25
X_NAME( 1 )-x1-5
*/可变参数
1
#define DEBUGP(format, ...) printk(format, ## __VA_ARGS__)
- 在C语言中,未定义的宏默认值为0。
1
2
3
4
5
6
7#if CONFIG_CHARGE_OUT_SHUTDOWN != 0
printf("CONFIG_CHARGE_OUT_SHUTDOWN is not equal to zero.\n");
#else
printf("CONFIG_CHARGE_OUT_SHUTDOWN is not defined or equal to zero.\n");
#endif
// 在上述代码中,由于 `CONFIG_CHARGE_OUT_SHUTDOWN` 没有被定义,`#if` 指令的条件不成立,所以第一个 `printf` 语句不会被编译。相反,由于存在 `#else` 部分,第二个 `printf` 语句会被编译并执行,输出 "CONFIG_CHARGE_OUT_SHUTDOWN is not defined or equal to zero."。
宏展开的顺序
带#和带##的运算符不需要进行参数的展开!!除了带#和##运算符的参数之外,其它参数在替换之前要对实参本身做充分的展开,所以应该先把sub_z展开成26再替换到alt[x]中x的位置。
1
2
3
4
5#define sh(x) printf("n" #x "=%d, or %d\n",n##x,alt[x])
#define sub_z 26
sh(sub_z)
//展开成了printf("n" "sub_z" "=%d, or %d\n",nsub_z,alt[26])
强制转换
signed int转换到unsigned int
带符号整型转换到无符号整型,最高位(high-order bit)会丧失其作为符号位的功能。如果该带符号整数的值非负,那么转换后值不变;如果该带符号整数的值为负,那么转换后的结果通常是一个非常大的正数。
uint32_t 无符号相减 定时器溢出问题
1 | |
这个uint32_t的_timer_ticks,每毫秒自加1,设备运行到49天的时候会涉及到溢出的问题。所以在timer_loop里面的判断超时的语句需要小修改下。
if(_timer_ticks >= target->timeout)
修改为
if((int)((uint32_t)(target->timeout -_timer_ticks)) <= 0)
完美解决uint32_t变量溢出时,超时判断有误的bug
HAL库的无符号相减,tick是++
1 | |
RT-thread 内的判断
1 | |
这里其实涉及的是无符号数相减,减出负数
负数在计算机内是用其补码来存储的。
减法会被换算成两个数的加法,a-b会被换算成a加上b的补码,即a+(~b+1)。
252-250=(b1111 1100)+(b0000 0110)=(b0000 0010)=2
1-250=(b0000 0001)+(b0000 0110)=(b0000 0111)=7
所以计算两值的差值就可以直接相减
1 | |
c编译原理
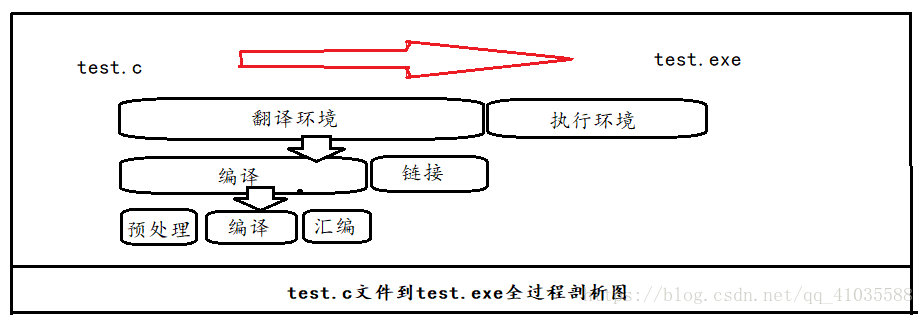

预编译
- define展开
- FILE LINE等展开
- include包含
- 转化 .i 文件
1 | |
编译
- 优化在这进行,包括数值计算一类
- 编译成汇编文件
- 转化 .s .asm文件
1 | |
汇编
- 汇编语言代码翻译成目标机器指令的过程
- data段code段在这里产生
- 转化 .o .obj文件
1 | |
链接
- 链接成 .exe .out .axf等
- 动态链接、静态链接(动态库.so、静态库.a)
1 | |
内存分配相关
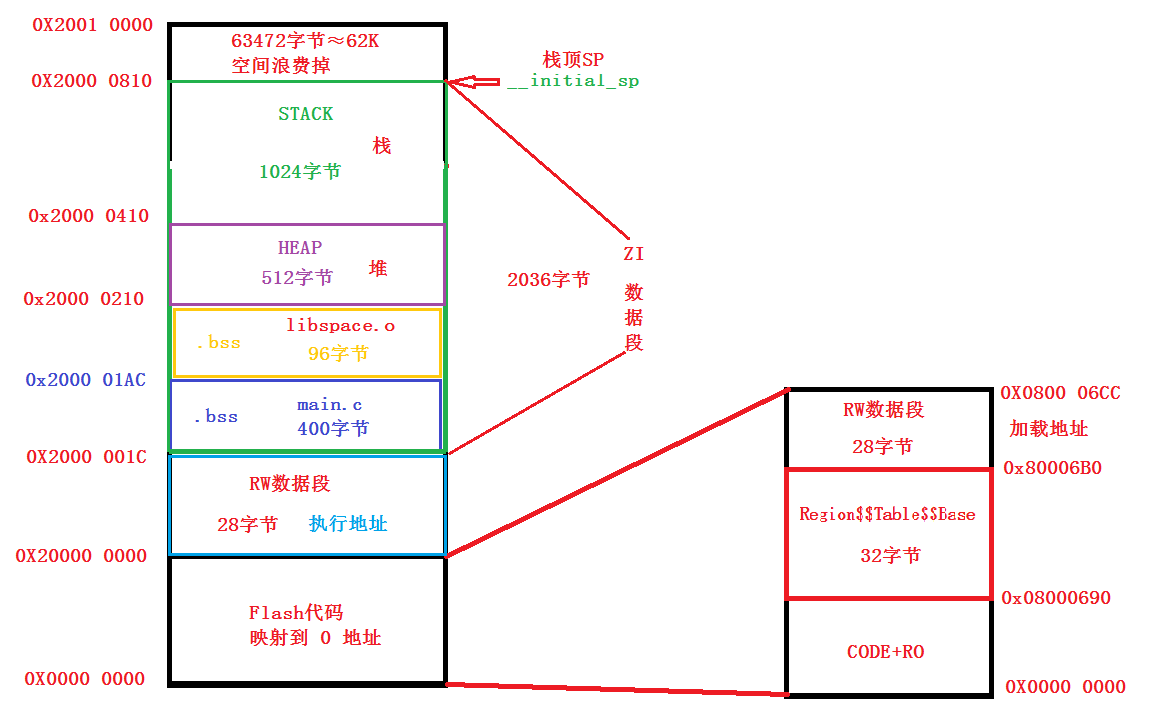
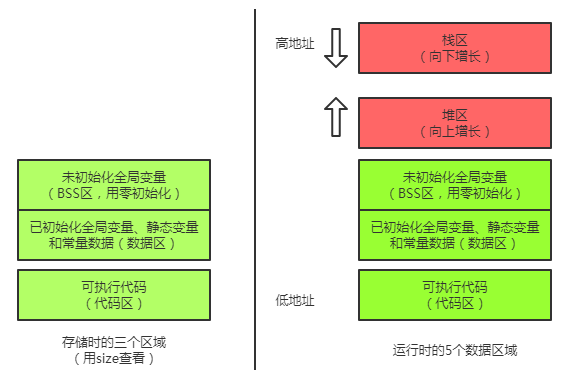
.code 代码区
代码段(code segment/text segment )通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
STM32 在上电启动之后默认从 Flash 启动, 在STM32里面Code部分不会被搬运到RAM内
.data 已初始化区
.bss 未初始化区
heap 堆区
stack 栈区

- 在C语言中,函数参数的入栈顺序是从右到左
new delete malloc free
free两次有时可能是极其严重的安全漏洞,将一个指针释放两次是非常危险的行为,它可能造成任意代码执行。 参考
new / delete
- Allocate / release memory 分配/释放
- Memory allocated from ‘Free Store’. 这个FreeStore和Heap不一定一样 似乎取决于它的具体实现方式
- Returns a fully typed pointer.
new(standard version) never returns aNULL(will throw on failure).- Are called with Type-ID (compiler calculates the size). 使用 Type-ID 调用(编译器计算大小)。
- Has a version explicitly to handle arrays. 有一个明确的版本来处理数组。
- Reallocating (to get more space) not handled intuitively (because of copy constructor). 重新分配(以获得更多空间)没有直观地处理(因为复制构造函数)。
- Whether they call
malloc/freeis implementation defined. 他们是否调用malloc/free是由实现来定义的。 - Can add a new memory allocator to deal with low memory (
std::set_new_handler). operator new/operator deletecan be overridden legally.- Constructor / destructor used to initialize / destroy the object. 构造函数/析构函数用于初始化/销毁对象。
malloc / free
- Allocate / release memory
- Memory allocated from ‘Heap’.
- Returns a
void*. - Returns
NULLon failure. - Must specify the size required in bytes. 必须以字节为单位指定所需的大小。
- Allocating array requires manual calculation of space. 分配数组需要手动计算空间。
- Reallocating larger chunk of memory simple (no copy constructor to worry about). 重新分配更大的内存块很简单(无需担心复制构造函数)。
- They will NOT call
new/delete. - No way to splice user code into the allocation sequence to help with low memory. 无法将用户代码拼接到分配序列中以帮助解决内存不足的问题。
malloc/freecan NOT be overridden legally.
Table comparison of the features:
| Feature | new / delete | malloc / free |
|---|---|---|
| Memory allocated from | ‘Free Store’ | ‘Heap’ |
| Returns | Fully typed pointer | void* |
| On failure | Throws (never returns NULL) | Returns NULL |
| Required size | Calculated by compiler | Must be specified in bytes 必须以字节为单位指定 |
| Handling arrays 处理数组 | Has an explicit version | Requires manual calculations |
| Reallocating 重新分配 | Not handled intuitively | Simple (no copy constructor) |
| Call of reverse | Implementation defined | No |
| Low memory cases | Can add a new memory allocator 可以添加新的内存分配器 | Not handled by user code 不由用户代码处理 |
| Overridable | Yes | No |
| Use of constructor / destructor 构造函数/析构函数的使用 | Yes | No |
| Type | 运算符 | 函数 |
Technically, memory allocated by new comes from the ‘Free Store’ while memory allocated by malloc comes from the ‘Heap’. Whether these two areas are the same is an implementation detail, which is another reason that malloc and new cannot be mixed. 从技术上讲,分配的内存new来自“免费存储”,而分配的内存malloc来自“堆”。这两个区域是否相同是一个实现细节,这是另一个malloc不能new混为一谈的原因。
最相关的区别是
new运算符分配内存然后调用构造函数,delete调用析构函数然后释放内存。- 严格来说,new 操作符只是分配内存。是 new 表达式调用 new 运算符,然后在分配的内存中运行构造函数。
new调用对象的ctor,delete调用dtor。malloc&free只是分配和释放原始内存。
复合字面量(Compound Literals)
字面量是除了符号常量之外的常量。
如,1是int型字面量,3.14是float型字面量,’C’是char型字面量,’Yudao’是字符串字面量。
那么,数组和结构体是否也能有字面量来表示呢?
因此,C99标准委员会就新增了复合字面量(compound literals)。
语法
( type-name ) { initializer-list }
( type-name ) { initializer-list , }
约束
The type name shall specify an object type or an array of unknown size, but not a variable length array type.
type name指定了数组类型或结构体类型,数组长度不能是可变的。No initializer shall attempt to provide a value for an object not contained within the entire unnamed object specified by the compound literal.
匿名”对象”的初始化必须在在复合字面量的大括号中。If the compound literal occurs outside the body of a function, the initializer list shall consist of constant expressions.
如果复合字面量是文件作用域,initializer list的表达式必须是常量表达式。
使用
例如下面是一个普通的数组声明。
1 | |
下面创建了一个和age数组相同的匿名数组,也有两个int类型值
1 | |
注意去掉申明中的数组名,留下的int[2]就是复合字面量的类型名。
因为复合字面量是匿名的,所以不能先创建然后再使用它,必须在创建的同时使用它。
一般需要这样定义使用:
1 | |
一些应用
1 | |
1 | |
内建函数
STM32相关
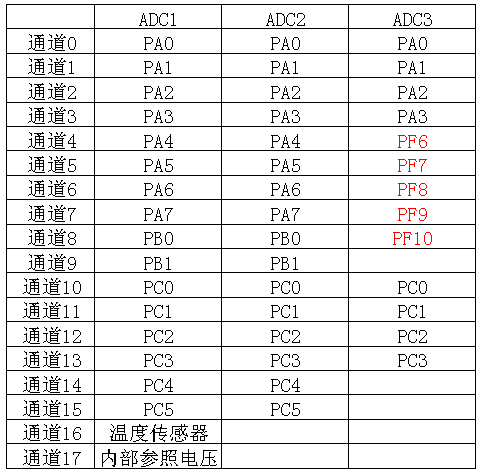
ADC 与 通道映射关系
Printf第一个字符丢失
- 将发送放在等待标志位后面即可解决问题
1 | |
通用TIM PWM输出低电平
调用 TIM_CCxCmd 关闭输出使能即可持续输出低电平
1 | |
| CCxE位 | OCx输出状态 |
|---|---|
| 0 | 禁止输出(OCx=0,OCx_EN=0) |
| 1 | OCx = OCxREF + 极性,OCx_EN=1 |
杂乱笔记
仿真建议使用SWD模式(使用的线少) emmm。。。。?
KEY_UP高电有效(可用于唤醒)、KEY0、KEY1低电有效
编译器会默认把没有赋值的变量自动赋值为0(真的是这样吗?,局部变量呢?答复:局部变量不会被初始化,请一定注意要去手动进行初始化)
NTC (Negative Temperature Coefficient 负温度系数) PTC (Positive 正温度系数)
RTC (实时时钟)
APB1和APB2的区别,
APB1操作速度限于36MHz, 上面连接的是低速外设,包括 TIM234567、WWDG、SPI2、SPI3、USART23、UART45、CAN12、PWRPower interface clock、 BKP、 DAC、I2C12、等,具体请参考7.3.8章节APB1外设使能寄存器
APB2操作速度全速, 上面连接的是高速外设,包括 UART1 、SPI1、Timer1、ADC1、ADC2、所有普通 IO 口(PA-PE)(PA-PE)(PA-PE)(PA-PE)(PA-PE)(PA-PE) 、第二功能IO 口 、具体请参考7.3.7章节APB2外设使能寄存器原子提供的delay_ms 最大是1864ms不能超过这个值
volatile 简单地说就是防止编译器对代码进行优化。
enum 枚举类型
SysTick LOAD 转载到 VAL 需要时钟周期所以计算 LOAD 时需要-1
PA13 PA14 PA15 PB3 PB4 上电默认是SWD+JTAG模式所以这些GPIO口不能直接使用可调用 GPIO_PinRemapConfig 函数修改
DAC要将对应的IO设置成模拟输入!!!
USART1 时钟脉冲来源 PCLK2 USART2-4来源 PCLK1
使用USART不需要使能AFIO (发生重映射才需要进行打开AFIO参考CSDN)
0,1,2,3,4 各有自己的中断函数 5-9共用一个中断函数 10-15共用一个中断函数
u8 temp attribute((at (地址))); //需要定义为全局变量—-定义变量到指定地址
容量
4表示16KB (小容量ld)
6表示32KB (小容量ld)
8表示64KB (中容量md)
B表示128KB (中容量md)
C表示256KB (大容量hd)
E表示512KB (大容量hd)
F表示768KB (超大容量xl)
G表示1024KB (超大容量xl)ADC输入范围:VREF- ≤ VIN ≤ VREF+
在扫描模式下,由ADC_SQRx或者ADC_JSQRx寄存器选中的通道被转换。如果设置了EOCIE或者JEOCIE,在最后一个通道转换完毕后才会产生EOC或者JEOC中断。
ADC ADC1通道17 测得的是内部参考电压(根据数据手册中的数据,这个参照电压的典型值是1.20V,最小值是1.16V,最大值是1.24V),!!!不是ADC的参考电压Vref+!!!
系统滴答定时器
SysTick->CTRL 类似控制及状态位寄存器
SysTick->LOAD 到时间自动重装的重装载寄存器
SysTick->VAL 当前数值寄存器
SysTick->CALIB 校准数值寄存器(暂时没有用到)
RTOS相关
进程 线程 协程
进程
进程的概念
进程 – 是现代操作系统的一个基本概念,是并发程序出现后出现的一个重要概念,它是指 程序在一个数据集合上运行的过程,是系统进行资源分配和调度运行的一个独立单位,有时 也称为活动、路径或任务。
- 资源分配的最小单位(拥有独立的地址空间,同一个进程内的线程共享进程地址空间)
- 进程是程序执行的实例
- 我的理解是在windows里面每一个程序启动都会有一个进程的存在,这个进程会有一个虚拟的地址空间。(而在STM32一类芯片内是没有虚拟地址空间的,如果跑了RTOS,系统所调度的其实是进程的子项线程)
我们都知道计算机的核心是CPU,它承担了所有的计算任务;而操作系统是计算机的管理者,它负责任务的调度、资源的分配和管理,统领整个计算机硬件;应用程序则是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,从来没有统一的标准定义。
进程一般由程序、数据集合和进程控制块三部分组成。
- 程序用于描述进程要完成的功能,是控制进程执行的指令集;
- 数据集合是程序在执行时所需要的数据和工作区;
- 程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程具有的特征:
- 动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
- 并发性:任何进程都可以同其他进程一起并发执行;
- 独立性:进程是系统进行资源分配和调度的一个独立单位;
- 结构性:进程由程序、数据和进程控制块三部分组成。
线程
线程的概念
线程– 是进程中的一个实体,是被系统调度和分配的基本单元。 每个程序至少包含一个线 程,那就是主线程。 线程自己只拥有很少的系统资源(如程序计数器、一组寄存器和栈), 但它可与同属一个进程的其他线程共享所属进程所拥有的全部资源,同一进程中的多个线程 之间可以并发执行,从而更好地改善了系统资源的利用率。
- 程序执行的最小单位
- CPU调度最小单位,一个进程并发多个线程
线程是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。
一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。
而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
如上图,在任务管理器的进程一栏里,有道词典和有道云笔记就是进程,而在进程下又有着多个执行不同任务的线程。
协程
- 它是基于线程的,一个线程内有多个协程
- 由程序员自行管理的更加轻量的线程
协程
协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做『用户空间线程』,具有对内核来说不可见的特性。
因为是自主开辟的异步任务,所以很多人也更喜欢叫它们纤程(Fiber),或者绿色线程(GreenThread)。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程的目的
在传统的J2EE系统中都是基于每个请求占用一个线程去完成完整的业务逻辑(包括事务)。所以系统的吞吐能力取决于每个线程的操作耗时。如果遇到很耗时的I/O行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底。
最常见的例子就是JDBC(它是同步阻塞的),这也是为什么很多人都说数据库是瓶颈的原因。这里的耗时其实是让CPU一直在等待I/O返回,说白了线程根本没有利用CPU去做运算,而是处于空转状态。而另外过多的线程,也会带来更多的ContextSwitch开销。
对于上述问题,现阶段行业里的比较流行的解决方案之一就是单线程加上异步回调。其代表派是node.js以及Java里的新秀Vert.x。
而协程的目的就是当出现长时间的I/O操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除ContextSwitch上的开销。
协程的特点
- 线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
- 线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程。
- 由于在同一个线程上,因此可以避免竞争关系而使用锁。
- 适用于被阻塞的,且需要大量并发的场景。但不适用于大量计算的多线程,遇到此种情况,更好实用线程去解决。
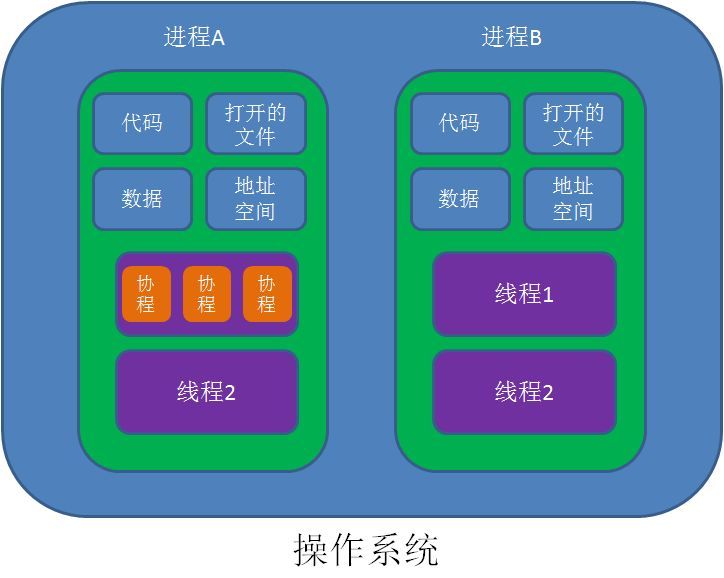
进程和线程关系
- 资源分配给进程,同一进程内的所有线程共享该进程的所有资源;
- 同一个进程的线程之间可以直接交流;两个进程想通信,必须通过一个中间代理来实现;
- 处理机分配给线程,即真正在处理机上运行的是线程;
- 线程共享内存空间;进程的内存是独立的;
- 系统开销:在创建和撤销进程的时候,系统都要分配和回收资源,导致系统的明显大于创建和撤销线程时的开销。但进程有独立的地址空间,进程崩溃后,在保护模式的下不会对其他进程造成影响,而线程只是进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有独立的地址空间,一个线程死后就等于整个进程死掉,所以多进程程序要比多线程程序健壮,但是在进程切换的时候消耗的资源较大,效率差。
- 多线程执行效率高; 多进程耗资源,安全。
互斥量和信号量的区别
1. 互斥量用于线程的互斥,信号量用于线程的同步。
这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
2. 互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
3. 互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
外设
I2C
I2C,也称为 I2C 或 IIC,是飞利浦半导体于 1982 年发明的同步、多主/多从(控制器/目标)、分组交换、单端串行通信总线。
I2C仅使用两条双向集电极开路或漏极开路线路:串行数据线(SDA)和串行时钟线(SCL),由电阻上拉。使用的典型电压为+5 V或+3.3 V,但允许使用其他电压的系统。
I2C从机地址有7位、8位、10位不同的地址空间,一般来说7位比较常见。
I²C的参考设计使用一个7比特长度的地址空间但保留了16个地址,所以在一组总线最多可和112个节点通信[a]。在7位寻址过程中,从机地址在启动信号后的第一个字节开始传输,该字节的前7位为从机地址,第8位为读写位,其中0表示写,1表示读。
虽然最大的节点数目是被地址空间所限制住,但实际上也会被总线上的总电容所限制住,一般而言为400 pF。
注意:
调试的时候需要注意设备地址是已经左移之后的还是未左移的!

参考上面的图像我们可以看到,
START:
- 在SCL信号为 高 的时候,SDA由 高 变 低 是START信号。
- (助记,SCL的高电平状态下SDA不允许变化,除非是start信号或者stop信号。空闲状态SCL和SDA都是高电平,start和stop都是由SDA产生的信号)
DATA TRANSMISSION:在数据传输阶段,
- 蓝色阶段:SCL被拉低,此时SDA变成特定电平。
- 绿色阶段:SCL被拉 高 (图中B1),SDA的电平不允许变化。数据在SCL的 上升沿 进行采样。
STOP:
- 在SCL信号为H的时候,SDA由L变H是STOP信号。
通信速率
双向通信速度(模式):
允许任意低的时钟频率
10 kbit/s:低速模式
100 kbit/s:标准模式,Standard-mode (Sm);
400 kbit/s:快速模式,Fast-mode (Fm);
1 Mbit/s:快速模式+,Fast-mode Plus (Fm+);
3.4Mbit/s:高速模式,High-speed mode (Hs-mode);
单向通信速度(模式):
5 Mbit/s:超快模式,UItra Fast-mode (UFm)。
SPI
串行外设接口(SPI)是一种同步串行通信规范,主要用于嵌入式系统,用于芯片(电子设备)之间的短距离有线通信。摩托罗拉在 1980 年代中期开发了该规范,该规范已成为具有许多变体的事实标准。
调试SPI千万要注意CPOL CPHA大部分通信异常都是出现在这里
SPI有四个逻辑信号
- SCLK : Serial Clock (clock signal from main)
- MOSI : Main Out Sub In (data output from main)
- MISO : Main In Sub Out (data output from sub)
- CS : Chip Select (active low signal from main to address devices and initiate transmission 从主设备到寻址设备并启动传输的低电平有效信号)
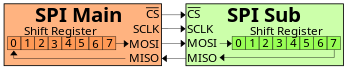
一对一SPI
使用单个主器件和单个子器件的基本 SPI 配置。每个器件在内部使用移位寄存器进行串行通信,它们共同构成一个片间循环缓冲器。
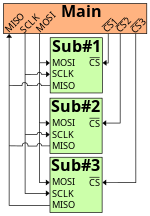
多点SPI
Multidrop SPI bus (多点SPI总线)
Daisy-chained SPI (菊花链式 SPI)

优缺点
优势
- 此协议默认全双工通信
- 推挽式驱动器(与漏极开路相反)提供良好的信号完整性和高速度
- 吞吐量高于 I²C 或 SMBus。不限于任何最大时钟速度,可实现高速运行
- 传输位的完全协议灵活性
- 不限于 8 位符号
- 任意选择消息大小、内容和用途
- 极其简单的硬件接口
- IC封装上仅使用4个引脚,比并行接口少得多
- 每个器件最多一独特信号(芯片选择);所有其他信号是共享的
- 信号是单向的,便于电气隔离
- 简单的软件实施
缺点
- 即使是三线式SPI,也需要比I²C更多的IC线路
- 无带内寻址;共享总线上需要带外芯片选择信号
- 子没有硬件流控制(但主可以延迟下一个时钟边沿以降低传输速率)
- 不支持动态添加节点(热插拔)
- 没有从机检测机制,主机无法检测是否与从机断开。
- 通常仅支持一个主设备(取决于设备的硬件实现)
- 未定义错误检查协议
- 无法进行数据检验,不定义额外的协议时(如CRC)无法保证数据正确性。
- 与RS-232、RS-485或CAN总线相比,只能处理短距离。(通过使用RS-422等收发器可以延长其距离。
- 信号路径中的光隔离器限制了MISO传输的时钟速度,因为时钟和数据之间增加了延迟
- 双通道 SPI(Dual SPI)、四通道 SPI(Quad SPI) 和三线串行总线等一些变体是半双工的。
CKPOL (Clock Polarity) = CPOL = POL = Polarity = (时钟)极性
CKPHA (Clock Phase) = CPHA = PHA = Phase = (时钟)相位CPOL极性
先说什么是SCLK时钟的空闲时刻,其就是当SCLK在发送8个bit比特数据之前和之后的状态,于此对应的,SCLK在发送数据的时候,就是正常的工作的时候,有效active的时刻了。其英文精简解释为:Clock Polarity = IDLE state of SCK。
SPI的CPOL,表示当SCLK空闲idle的时候,其电平的值是低电平0还是高电平1:
CPOL=0,时钟空闲idle时候的电平是低电平,所以当SCLK有效的时候,就是高电平,就是所谓的active-high;
CPOL=1,时钟空闲idle时候的电平是高电平,所以当SCLK有效的时候,就是低电平,就是所谓的active-low;从上图中可以看出,(CPOL=0)的SCK 波形,它有(传输)8 个脉冲,而在脉冲传输前和完成后都保持在【低电平状态】。
此时的状态就是时钟的空闲状态或无效状态,因为此时没有脉冲,也就不会有数据传输。同理得出,(CPOL=)1 的图,时钟的空闲状态或无效状态时SCK 是保持【高电平的】。CPHA相位
首先说明一点,capture strobe = latch = read = sample,都是表示数据采样,数据有效的时刻。
相位,对应着数据采样是在第几个边沿(edge),是第一个边沿还是第二个边沿,0对应着第一个边沿,1对应着第二个边沿。对于:CPHA=0,表示第一个边沿:
对于CPOL=0,idle时候的是低电平,第一个边沿就是从低变到高,所以是上升沿;
对于CPOL=1,idle时候的是高电平,第一个边沿就是从高变到低,所以是下降沿;CPHA=1,表示第二个边沿:
对于CPOL=0,idle时候的是低电平,第二个边沿就是从高变到低,所以是下降沿;
对于CPOL=1,idle时候的是高电平,第一个边沿就是从低变到高,所以是上升沿;数据是在SCK的第一个时钟边沿保持稳定【数据被采样捕获】,在下一个边沿改变【SCK 的下降沿数据改变】
SPI mode Clock polarity (CPOL) 极性 Clock phase (CPHA) 相位 Data is shifted out on
数据移出Data is sampled on
数据采样0 0 0 falling SCLK, and when CS activates rising SCLK 1 0 1 rising SCLK, and when CS activates falling SCLK 2 1 0 falling SCLK rising SCLK 3 1 1 rising SCLK falling SCLK
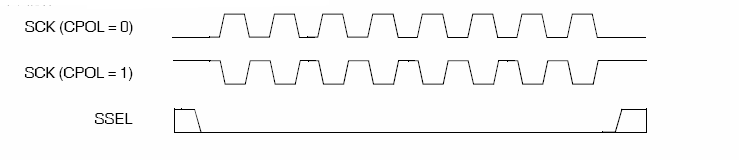
SPI 变种 SingleSPI DualSPI QuadSPI OctoSPI
Single SPI
SPI 适用于大多数用例,例如快速原型设计、设备编程和自动化测试。SPI 速度很快,大多数Single SPI串行吞吐率达到 10 Mbps 左右。然而,单条数据线将无法以SPI最快的速度发送数据。 多 I/O SPI能够支持单个设备增加吞吐量。
SPI 本身是全双工的。Dual SPI Quad SPI都是半双工,因为使用 2-4 个引脚来发送和接收。切换到双 SPI 或四 SPI 是通过在单 SPI 模式下发送命令字节来完成的。命令字节将在Dual SPI或Quad SPI下请求响应。
Dual SPI
Dual SPI 具有双 I/O 接口,与标准串行闪存设备相比,传输速率提高了一倍。MISO 和 MOSI 数据引脚以半双工模式运行,每个时钟周期发送两位。MOSI 线变为 IO0,MISO 线变为 IO1。
Quad SPI
Quad SPI 与 Dual SPI 类似,以半双工模式运行,但吞吐量提高了四倍。添加了两条额外的数据线,每个时钟周期传输 4 位。数据线现在为 IO0、IO1、IO2 和 IO3。
Octo SPI
与 Dual SPI 类似,以半双工模式运行,但吞吐量提高了八倍。每个时钟周期传输 8 位。
Camera
VGA,即分辨率为 640 * 480 的输出模式;
QVGA,即分辨率为 320 * 240 的输出模式;
QQVGA,即分辨率为 160 * 120 的输出模式
SCCB
SCCB 全称是:Serial Camera Control Bus 即串行摄像头控制总线,是由 OV(OmniVision 的简称)公司定义和发展的三线式串行总线。不过,OV 公司为了减少传感器引脚的封装,现在SCCB 总线大多采用两线式接口总线。
SCCB 与 I2C极其相似。
SD卡
SD 卡主要有 SD、Mini SD 和 microSD(原名 TF 卡,2004 年正式更名为 Micro SD Card)
Mini SD 已经被 microSD 取代,使用得不多。
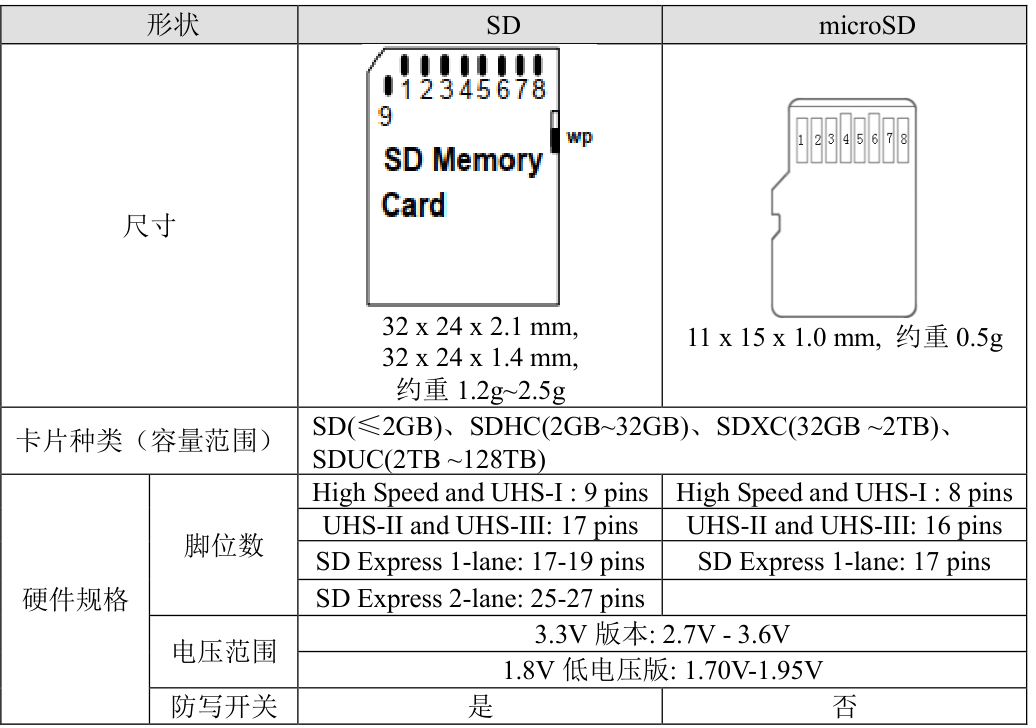
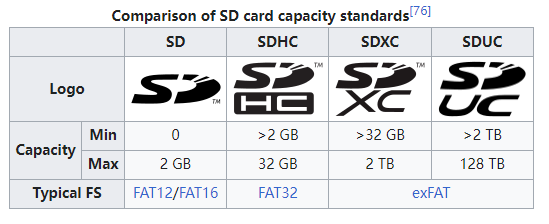
容量
速度
Bus speed
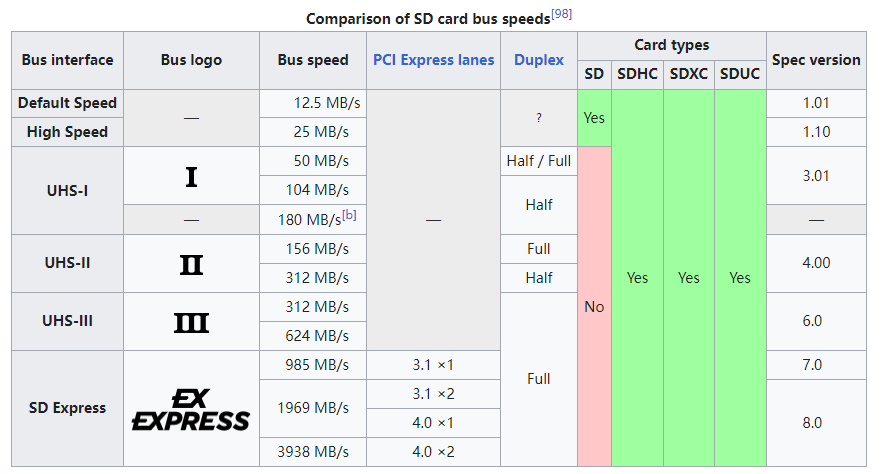
Video Speed Class
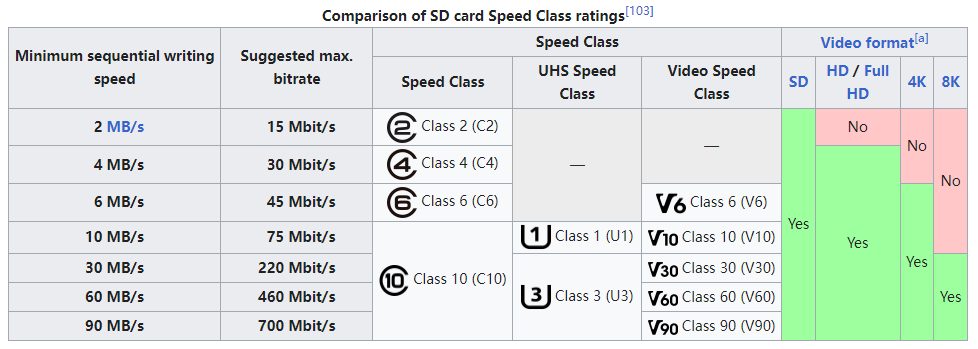
Application Performance Class

“×” Class
“×” Class是标准CD-ROM驱动器速度 150 KB/s (大约 1.23 Mbit/s)的倍数,由一些卡制造商使用,并因速度等级而被废弃。基本卡传输数据的速度高达 CD-ROM 速度的六倍 (6×);即 900 kbit/s 或 7.37 Mbit/s。
制造商可能会报告最佳情况的速度,也可能会报告卡的最快读取速度,该速度通常比写入速度更快。
当卡同时列出 speed class 和 “×” Class时,后者可以被假定为仅读取速度。
SDIO 接口
Pin
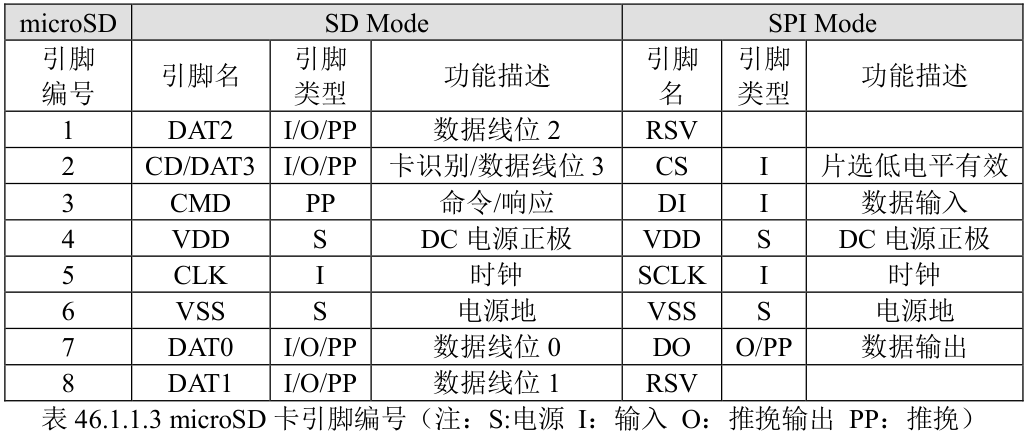
Reg

Instruction set architecture 指令集架构
Instruction set architecture(ISA)
一般来说,市场上流通的ISA有两种类型。它们是 RISC 和 CISC 架构。RISC 代表精简指令集计算机(Reduced Instruction Set Computer),而 CISC 代表复杂指令集计算机(Complex Instruction Set Computer)。
这两种架构如今都很流行,x86(英特尔和 AMD 处理器)是顶级处理器,而 ARM(高通和联发科处理器)是最流行的 RISC 架构。
RISC 架构中使用的较少指令和其他优化技术使这些类型的处理器使用更少的功耗,使其成为智能手机、相机、智能手表和各种物联网设备的理想选择。
RISC-V
RISC-V是一种基于RISC的开放标准ISA,任何人都可以使用它来设计自己的芯片,而无需支付许可费。其开源特性允许对 RISC-V ISA 进行进一步修改和扩展,以制造用于特定任务的专用芯片。
ARM
ARM 是一种基于 RISC 的闭源 ISA,授权给公司使用其处理器和 SoC。
x86
内建函数 builtin
Other Built-in Functions Provided by GCC
内建函数的函数命名,通常以 __builtin 开头。这些函数主要在编译器内部使用,主要是为编译器服务的。
GCC 还提供了大量内置函数。其中一些是用于处理异常或可变长度参数列表的内部用途,这里不再赘述,因为它们可能会随时更改;我们不建议广泛使用这些函数。
其余函数是为了优化目的而提供的。
__builtin_expect
您可以使用__builtin_expect来为编译器提供分支预测信息。
1 | |
__builtin_bswap32 64
— 内置函数:int32_t __builtin_bswap32 ( int32_t x )
返回按字节顺序反转的 x
0xaabbccdd;例如,变为0xddccbbaa。此处的字节始终表示正好 8 位。
— 内置函数:int64_t __builtin_bswap64 ( int64_t x )
与 类似
__builtin_bswap32,只是参数和返回类型是 64 位。
__builtin_return_address
获取当前函数调用的返回地址。这个函数通常用于调试和分析程序的调用栈。
1 | |
level参数是一个无符号整型值,表示调用栈的深度。level为 0 时,返回当前函数的返回地址;level为 1 时,返回调用当前函数的函数的返回地址;- 以此类推。
__builtin_frame_address
在函数调用过程中,还有一个“栈帧”的概念。函数每调用一次,都会将当前函数的现场(返回地址、寄存器等)保存在栈中,每一层函数调用都会将各自的现场信息都保存在各自的栈中。
这个栈也就是当前函数的栈帧,每一个栈帧有起始地址和结束地址,表示当前函数的堆栈信息。多层函数调用就会有多个栈帧,每个栈帧里会保存上一层栈帧的起始地址,这样各个栈帧就形成了一个调用链。
1 | |
level参数是一个无符号整型值,表示调用栈的深度。level为 0 时,返回当前函数的返回地址;level为 1 时,返回调用当前函数的函数的返回地址;- 以此类推。
嵌入式高效位算法
参考资料:
The Aggregate Magic Algorithms
WORDBITS: 数据宽度
位逆序
1
在整数x中反转位有点痛苦,但这里有一个32位值的SWAR算法:
1 | |
也可以重写这个算法,使用4个而不是8个常量,从而节省一些指令带宽。在我的1.2GHz Athlon(雷鸟)上,这种差别太小了,无法可靠地测量。下面是另一个版本:
1 | |
8位查表
1 | |
16位查表
1 | |
整数平均值
1 | |
原理:
这实际上是“众所周知”事实的扩展,对于二进制整数值
x和y,(x + y)等于((x&y)+(x | y))等于((x ^ y)+ 2 *(x&y ))。给定两个整数值
x和y,平均值的(底数)通常将由(x + y)/ 2计算;不幸的是,由于溢出,这可能会产生错误的结果。一个非常偷偷摸摸的替代方法是使用(x&y)+(((x ^ y)/ 2)。如果我们由于C没有指定是否对移位进行签名而意识到潜在的不可移植性,则可以将其简化为(x&y)+((x ^ y)>> 1)。无论哪种情况,好处是此代码序列都不会溢出。
整数求最大最小值
1 | |
解释
WORDBITS是数据宽度(8,16,32,……)
原理
((x-y)>>(WORDBITS-1)) 相当于取出符号位
当x>y时结果是0
注意! 当x
注意! 负数的移位似乎不太一样(当有符号整数右移时,最左边的位的值被复制到其他位),( 不幸的是,这种行为是特定于体系结构的)
同样的可以利用这一点应用到其他算法中:整数选择赋值
整数选择赋值
1 | |
原理
参考整数求最大最小值
没有临时值,交换值两数据的值
1 | |
注意:
但是当x和y之间的大小有显著差异时,较小的大小的值可能会严重损失准确性。例如,如果x的模比y大得多,那么(x+y)==x,最后得到y=0。
这里如果变量的存储大小很小 还可能会产生溢出 计算出来的数据就会问题了
计算byte内有多少bit置1
此为 汉明距离 问题
循环
just
Bit1 Bit0数量相关
1 | |
查表
8位查表 4位查表
合并计数(优)
以0x34520为例,b0011 0100 0101 0010 0000
第一步:每2位为一组,组内高低位相加
1 | |
第二步:每4位为一组,组内高低位相加
1 | |
第三步:每8位为一组,组内高低位相加
1 | |
第四步:每16位为一组,组内高低位相加
1 | |
第五步:每32位为一组,组内高低位相加
1 | |
这样最后得到的00000000 00000111即7即34520二进制中1的个数。
1 | |
__builtin_ctz
这个函数作用是返回输入数二进制表示从最低位开始(右起)的连续的0的个数;即 尾随 0 的位数
1 | |
__builtin_clz
这个函数作用是返回输入数二进制表示从最高位开始(左起)的连续的0的个数;即 前导 0 位数
__builtin_ffs
这个函数作用是返回输入数二进制表示的最低非0位的下标,下标从1开始计数;如果传入0则返回0。
__bulitin_popcount
这个函数作用是返回输入的二进制表示中1的个数;如果传入0则返回 0 。
__builtin_parity
这个函数作用是返回输入的二进制表示中1的个数的奇偶,也就是输入的二进制中1的个数对2取模的结果。
性能优化
Duff’s device
循环展开尝试通过每次迭代执行一批循环体来减少检查循环是否完成所需的条件分支的开销。
为了处理迭代次数不能被展开循环增量整除的情况,汇编语言程序员的常用技术是直接跳转到展开循环体的中间来处理余数。
Duff 在 C 中通过使用 C 的case label drop-through功能跳转到展开的正文中来实现此技术。
Duff’s device 利用了C语言的一些特性:
- case语句后面的break语句不是必须的。
- 在switch语句内,case标号可以出现在任意的子语句之前,甚至运行出现在if、for、while等语句内。(在这个设备发明之前,c语言是初版,switch语句的规范较为宽松)
尽管在 C 语言中有效,但 Duff 的设备违反了常见的 C 准则,例如MISRA 准则。某些编译器仅限于此类准则,因此可能会拒绝 Duff 的设备。
C语言示例
1 | |
描述语言示例
1 | |
功能一致的等效展开
1 | |
memcpy
他主要的思路是将文件分块尽量大些,让总线一次读取的数据全部可用。并一次拷贝多个数据,避免if等待。
这个程序的性能经过对比可以比直接赋值的情况下高8倍以上,count值较大的情况下。
1 | |
规范性
头文件
- common.h作为顶层头文件,主要放置(f10x.h、通用define、通用enum、),不得包含用户头文件以避免循环依赖。
- #ifndef标识符规范,前面加两个下划线 __COMMON_H
命名
| 类型 | 规则 | 详细 | 例子 |
|---|---|---|---|
| 全局变量 | 前面加 g | gRoomHmidity | |
| 指针 | 前面加 p | pHumidity | |
| 有符号变量 | 前面加i | iTemperature | |
| struct函数指针 | 前面加f(可选的) | fGetVal | |
| 不允许直接访问 | 前面加_ | _DataVal | |
| enum | 变量前面加 e | eFlag | |
| 值全大写即可 | ERR_OK | ||
| Typedef | 后面加 _t | uint32_t | |
- 不要使用八进制,误认是十进制。
- Switch default无操作需要得到注释。
- 禁止变量未赋值就进行使用。
- 如果某常量与其他常量密切相关,在定义中应该明确表示出此关系。
1 | |
- 通讯过程中使用的结构,必须注意字节序。
- 宏定义中尽量不使用return、goto、continue、break等改变程序流程的语句。
- 避免使用危险函数sprintf /vsprintf/strcpy/strcat/gets操作字符串
- 用strncpy()代替strcpy()
- 用strncat()代替strcat()
- 用snprintf()代替sprintf()
- 用fgets()代替gets()
特殊技巧及知识总结
- 字符串中可以使用\0OO(八进制)或\xHH(十六进制)来引用ASCII码中的符号。
1 | |
- if/else结构中尽量把TRUE概念较高的条件放到前面可以提高效率。
- 尽量把最有可能FALSE的子表达式放在“&&”的左边,同理尽量把最有可能为TRUE的子表达式放在“||”的左边。
1 | |
- 对于多维数组来说,”先行后列”的遍历效率会更高,但可能不明显。
- 如果某常量与其他常量密切相关,在定义中应该明确表示出此关系。
1 | |
如果输入参数传递的是一个ADT/UDT类型的参数(抽象数据类型/用户定义数据类型),宜采用
const &的方式来传递以提高效率。而对于int等类型的基本类型的参数没有必要改成const &传递。指针传递,提高效率。虽然类型名称和
*组合是一种指针类型,但是编译器是将*于后面的变量结合的,列如:
1 | |
- 多维数组中的指针
1 | |
- 字符数组是保存字符变量的数组,而字符串是以
\0结尾的字符数组。 - malloc/free和new/delete,这两者的区别主要有。new/delete是C++里的,更高级,更安全,返回的是有类型的指针,出错会抛出异常。
- 中断内不能使用除法
- 中断内有些指令需要较多的周期才能完成,它们是除法指令,双字传送指令LDRD/STRD以及多
重数据传送指令(LDM/STM)。对于前两者,CM3将为了保证中断及时响应而取消它们的执行。也就是中断内无法完成除法指令!!!
- 中断内有些指令需要较多的周期才能完成,它们是除法指令,双字传送指令LDRD/STRD以及多
- 调试模式如果单步调试,会屏蔽各种中断,定时器,IWDG都无法进行,而且定时器仍然在计数但是不会响应中断。
代码解析
1 | |
BUG 翻车集锦
TIM捕获触发DMA传输,但是在调试模式下DMA传出来的数据有问题。
把DMA出来的的数据再复制一份,复制出来的数据是没有问题的。
分析可能是,DEBUG下CPU停了,但是DMA总线还在跑,外设可能也是还在运行的,导致看起来DMA出来的数据有问题。
ADC矫正会发生ADC转换,如果有DMA配合使用,需要注意DMA需要在ADC矫正后使能。
隐式转换 小范围会转换成大范围 有一点特殊的是 unsigned int > int
运算符优先级!位运算符优先级较低
1 | |
- 运算符优先级!!!极注意!!! 请小心有位运算时打上括号 << 比 +- 要低
1 | |
0b110这种二进制写法似乎只有在GNU模式才被允许。STM32的看门狗是使得RST引脚拉低,来复位的。所以要注意复位电容的选择,太大会导致软件无法复位。
代码段内 \ 换行后不能接 /* xxx */ 注释,注释需要些在 \ 的前面,如 /* xxx */ \ 这样才行printf 内字符串问题
1
2
3
4
5
6# define DC_LOG_ERROR "\x11"
// 没有逗号 这是正常想要表达的逻辑, 前面的DC_LOG_ERROR 和 "%s:%d check SID Stasrt" 合并成一个表达式
printf(DC_LOG_ERROR "%s:%d check SID Stasrt",__func__, __LINE__);
// 有逗号 只会识别前面一个字符串 后面的都没了
printf(DC_LOG_ERROR, "%s:%d check SID Stasrt",__func__, __LINE__);
- 在 RSIC-V 的一个系统里面,系统会异常死机,报HardFault,报各种不一样的异常,排查后发现是32.768KHz的晶振所致,甚是奇怪!
- 系统异常一定要优先检查 系统各大件是否运行正常 SoC、Flash、晶振(主晶振、RTC晶振)、当然还有最重要的电源
- CRC XOR 各种校验的算法一定要确认一下多项式和初值,很多时候校验对不上都是这些的问题。