Python学习笔记
Content
Python学习笔记
printf
1 | |
格式化
基本格式化
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下
- 单个
1 | |
多个
1
2>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串
1 | |
format 格式化
format()它会用传入的参数依次替换字符串内的占位符{0}、{1}……
1 | |
字符转义
1 | |
显示字符串的前部分长度
1 | |
input
幸好,input()可以让你显示一个字符串来提示用户,于是我们把代码改成:
1 | |
注释
1 | |
数据类型 和 算数运算符
整数、浮点数、字符串、布尔型(True、False(注意大小写))、空值
所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示,但是不能保证其不被改变
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 = 4 >>> -9//2 = -5 |
/除法计算结果是浮点数
//称为地板除,两个整数的除法仍然是整数(c整数除法)
编码(数据转换)
ord()函数获取字符的整数表示
>>> ord(‘中’)
20013
chr()函数把编码转换为对应的字符
>>> chr(25991)
‘文’
str通过encode()可以编码为bytes
>>> ‘ABC’.encode(‘ascii’)
b’ABC’
>>> ‘中文’.encode(‘utf-8’)
b’\xe4\xb8\xad\xe6\x96\x87’
要把bytes变为str,就需要用decode()
>>> b’ABC’.decode(‘ascii’)
‘ABC’
要计算str包含多少个字符,可以用len()函数
>>> len(‘ABC’)
3
>>> len(‘中文’)
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数
>>> len(b’ABC’)
3
>>> len(b’\xe4\xb8\xad\xe6\x96\x87’)
6
>>> len(‘中文’.encode(‘utf-8’))
6
‘ABC’和b’ABC’,
前者是str,在内存中以Unicode表示,一个字符对应若干个字节
后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节
List列表(类似数组)
创建
1 | |
Python内置的一种数据类型是list。list是一种有序的集合,可以随时添加和删除其中的元素。
>>> classmates = [‘Jack’, 180, 1.69]
>>> classmates
[‘Jack’, 180, 1.69]
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
‘Tracy’
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append(‘Adam’)
>>> classmates
[‘Michael’, ‘Bob’, ‘Tracy’, ‘Adam’]
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, ‘Jack’)
>>> classmates
[‘Michael’, ‘Jack’, ‘Bob’, ‘Tracy’, ‘Adam’]
要删除list末尾的元素,用pop()方法:
>>> classmates.pop()
‘Adam’
>>> classmates
[‘Michael’, ‘Jack’, ‘Bob’, ‘Tracy’]
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
‘Jack’
>>> classmates
[‘Michael’, ‘Bob’, ‘Tracy’]
-———————————————————————————————————————
list元素也可以是另一个list,比如:
>>> s = [‘python’, ‘java’, [‘asp’, ‘php’], ‘scheme’]
>>> len(s)
4
要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了
>>> p = [‘asp’, ‘php’]
>>> s = [‘python’, ‘java’, p, ‘scheme’]
要访问’php’可以写p[1]或者s[2][1],因此s可以看成是一个二维数组
Tuple元组(静态数组)
另一种有序列表叫元组:tuple
。tuple和list非常类似,但是tuple一旦初始化就不能修改
>>> classmates = (‘Michael’, ‘Bob’, ‘Tracy’)
要定义一个只有1个元素的tuple,如果你这么定义:
1 | |
定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
1 | |
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的”tuple:
1 | |
str.replace 替换
1 | |
if 、 for 、 while 、 range
if
变体
1 | |
if age >= 18:
print(‘adult’)
else:
print(‘teenager’)
age = 3
if age >= 18:
print(‘adult’)
elif age >= 6:
print(‘teenager’)
else:
print(‘kid’)
for
所以for x in …循环就是把每个元素代入变量x,然后执行缩进块的语句。
再比如我们想计算1-10的整数之和,可以用一个sum变量做累加:
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum)
sum = 0
for x in range(101):
sum = sum + x
print(sum)
while
while循环
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
range
range(start, stop[, step]) 可以生成一个整数序列,
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
>>> list(range(5))
[0, 1, 2, 3, 4]
>>>range(10) # 从 0 开始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) # 步长为 5
[0, 5, 10, 15, 20, 25]
>>> range(0, 10, 3) # 步长为 3
[0, 3, 6, 9]
>>> range(0, -10, -1) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]
Dict(字典)
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下:
>>> d = {‘Michael’: 95, ‘Bob’: 75, ‘Tracy’: 85}
>>> d[‘Michael’]
95
1 | |
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | [dict.fromkeys(seq, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
文件操作
基本打开输出文件
1 | |
在这个程序中,第1行代码做了大量的工作。我们先来看看函数open() 。要以任何方式使用文件——哪怕仅仅是打印其内容,都得先打开 文件,这样才能访问它。函数open()接受一个参数:要打开的文件的名称。Python在当前执行的文件所在的目录中查找指定的文件。在这个示例中,当前运行的是file_reader.py,因此Python在file_reader.py所在的目录中查找pi_digits.txt。函数open() 返回一个表示文件的对象。在这里,open(‘pi_digits.txt’) 返回一个表示文件pi_digits.txt 的对象;Python将这个对象存储在我们将在后面使用的变量中。
关键字with 在不再需要访问文件后将其关闭。在这个程序中,注意到我们调用了open() ,但没有调用close() ;你也可以调用open() 和close() 来打开和关闭文件,但这样做时,如果程序存在bug,导致close() 语句未执行,文件将不会关闭。这看似微不足道,但未妥善地关闭文件可能会导致数据丢失或受损。如果在程序中过早地调用close() ,你会发现需要使用文件时它已关闭 (无法访问),这会导致更多的错误。并非在任何情况下都能轻松确定关闭文件的恰当时机,但通过使用前面所示的结构,可让Python去确定:你只管打开文件,并在需要时使用它,Python自会在合适的时候自动将其关闭。
删除字符串末尾的空白 rstrip
1 | |
相比于原始文件,该输出唯一不同的地方是末尾多了一个空行。为何会多出这个空行呢?因为read() 到达文件末尾时返回一个空字符串,而将这个空字符串显示出来时就是一个空行。要删除多出来的空行,可在print 语句中使用rstrip() :
每行左边的空格,为删除这些空格,可使用strip()
逐行读取文件
1 | |
文件打开模式
1 | |
在这个示例中,调用open() 时提供了两个实参(见❶)。第一个实参也是要打开的文件的名称;第二个实参(’w’ )告诉Python,我们要以写入模式 打开这个文件。打开文件时,可指定读取模式 (’r’ )、写入模式 (’w’ )、附加模式 (’a’ )附加到文件末尾、让你能够读取和写入文件的模式(’r+’ )。如果你省略了模式实参,Python将以默认的只读模式打开文件。
异常处理 try-except
1 | |
在这个示例中,try 代码块引发FileNotFoundError 异常,因此Python找出与该错误匹配的except 代码块,并运行其中的代码。最终的结果是显示一条友好的错误消息,而不是traceback:
一些方法
.count()
描述
Python count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法
count()方法语法:
1 | |
参数
- sub – 搜索的子字符串
- start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
.to_bytes()
(0x12).to_bytes(10, byteorder= ‘big’, signed = ‘true’)
10:表示转换后的数据占10个字节
byteorder:
1 | |
- signed: 表示有符号和无符号
函数名
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:(类似于指针????准确描述应该是类似 tpyedef )
1 | |
abs 绝对值
abs( x )函数 取绝对值
x – 数值表达式。
1 | |
max 找平均值
1 | |
max 找最大/小值
max( x, y, z, …. ) 可以接收任意多个参数,并返回最大的那个(可以传入list):
x – 数值表达式。y – 数值表达式。z – 数值表达式
1 | |
exal 执行字符串类型的表达式
eval(expression[, globals[, locals]])函数 函数用来执行一个字符串表达式,并返回表达式的值。
expression – 表达式。
globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
>>>x = 7
>>> eval( ‘3 * x’ )
21
>>> eval(‘pow(2,2)’)
4
a=eval(input(“请输入一个整数”)) #(自动类型转换)
int 强制转换
class int(x, base=10) 强制转换返回整型数据。
x – 字符串或数字。base – 进制数,默认十进制。
>>> int(‘0xa’,16)
10
>>> int(‘10’,8)
8
a=int(input(“请输入一个整数”)) #(强制类型转换)
type 判断对象类型
首先,我们来判断对象类型,使用type()函数:
基本类型都可以用type()判断:
1 | |
如果一个变量指向函数或者类,也可以用type()判断:
1 | |
但是type()函数返回的是什么类型呢?它返回对应的Class类型。如果我们要在if语句中判断,就需要比较两个变量的type类型是否相同:
1 | |
判断基本数据类型可以直接写int,str等,但如果要判断一个对象是否是函数怎么办?可以使用types模块中定义的常量:
1 | |
isinstance 判断类型是否相同
isinstance(object, classinfo) 如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False
object – 实例对象。
classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。
能用type()判断的基本类型也可以用isinstance()判断:
1 | |
并且还可以判断一个变量是否是某些类型中的一种,比如下面的代码就可以判断是否是list或者tuple:
1 | |
1 | |
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
dir 获得对象的所有属性和方法
如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list,比如,获得一个str对象的所有属性和方法:
1 | |
类似__xxx__的属性和方法在Python中都是有特殊用途的,比如__len__方法返回长度。在Python中,如果你调用len()函数试图获取一个对象的长度,实际上,在len()函数内部,它自动去调用该对象的__len__()方法,所以,下面的代码是等价的:
1 | |
二次三次方根
1 | |
math模块的一些方法
math.modf(分离小数和整数部分)
描述
modf() 方法返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
实例
以下展示了使用 modf() 方法的实例:
1 | |
以上实例运行后输出结果为:
1 | |
用户自定义函数
1 | |
(导入其他文件内的函数的方法)如果你已经把my_abs()的函数定义保存为abs.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from abs import my_abs来导入my_abs()函数,注意abs是文件名(不含.py扩展名):
1 | |
函数的返回值
1 | |
其实返回值是一个tuple(静态数组)!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
函数的传入参数
函数传入list要特别小心,函数内的修改会影响其本身,类似C中的指针对list产生了修改。
关键字传值(带**的传值)传入的是值,不会影响原来的内容。
函数的输入
函数的默认参数
默认参数。由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2:
1 | |
调用时可以 power(5) 直接计算5的2次方,也可以power(5,3)计算5的3次方。即默认参数可以传入也可以不传入。
定义默认参数要牢记一点:默认参数必须指向不变对象!
输入可变长变量
可变长度的传入变量,加了星号(*)的变量名会存放所有未命名的变量参数。
1 | |
关键字参数(字典(dict)参数)
1 | |
命名关键词参数
1 | |
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
1 | |
添加缺省值,从而简化调用:
1 | |
由于命名关键字参数city具有默认值,调用时,可不传入city参数:
1 | |
匿名函数lambda
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
1 | |
如下实例:
1 | |
面向对象编程
面向过程 和 面向对象的对比
Q:存储学生的信息并打印出来
面向过程
假设我们要处理学生的成绩表,为了表示一个学生的成绩,面向过程的程序可以用一个dict表示:
1 | |
而处理学生成绩可以通过函数实现,比如打印学生的成绩:
1 | |
面向对象
如果采用面向对象的程序设计思想,我们首选思考的不是程序的执行流程,而是Student这种数据类型应该被视为一个对象,这个对象拥有name和score这两个属性(Property)。如果要打印一个学生的成绩,首先必须创建出这个学生对应的对象,然后,给对象发一个print_score消息,让对象自己把自己的数据打印出来。
1 | |
给对象发消息实际上就是调用对象对应的关联函数,我们称之为对象的方法(Method)。面向对象的程序写出来就像这样:
1 | |
类、实例、方法和属性
- 类 Student
- 实例 jack
- 方法 print_score
- 属性 obj_name
- 增加属性 gender
1 | |
类 实例
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
仍以Student类为例,在Python中,定义类是通过class关键字:
1 | |
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
1 | |
方法
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
面向对象编程的一个重要特点就是数据封装。在上面的Student类中,每个实例就拥有各自的name和score这些数据。我们可以通过函数来访问这些数据,比如打印一个学生的成绩:
1 | |
但是,既然Student实例本身就拥有这些数据,要访问这些数据,就没有必要从外面的函数去访问,可以直接在Student类的内部定义访问数据的函数,这样,就把“数据”给封装起来了。这些封装数据的函数是和Student类本身是关联起来的,我们称之为类的方法:
1 | |
要定义一个方法,除了第一个参数是self外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了self不用传递,其他参数正常传入:
1 | |
Note:
- 实例增加属性
类相当于一个模板,用模板(类)定义实例后,实例还可以再加其他属性
1 | |
访问限制 private
外部无法访问,只能通过方法访问(私有变量)
1 | |
需要注意的是,在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量:
1 | |
但是强烈建议你不要这么干,因为不同版本的Python解释器可能会把__name改成不同的变量名。
总的来说就是,Python本身没有任何机制阻止你干坏事,一切全靠自觉。
最后注意下面的这种错误写法:
1 | |
表面上看,外部代码“成功”地设置了__name变量,但实际上这个__name变量和class内部的__name变量不是一个变量!内部的__name变量已经被Python解释器自动改成了_Student__name,而外部代码给bart新增了一个__name变量。不信试试:
1 | |
组合
用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python课程
1 | |
当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
继承 多态
- 抽象:抽象即抽取类似或者说比较像的部分。是一个从具题到抽象的过程。
- 继承:子类继承了父类的方法和属性
- 派生:子类在父类方法和属性的基础上产生了新的方法和属性
继承
- 建立一个新类(子类 Subclass)可以copy一份原来类(父类 基类或超类 Base class、Super class)的全部功能(方法、变量 等)
1 | |
- 当子类和父类都存在相同的
run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。
1 | |
多态
就是一个集合的概念,子类包含了父类,子类比父类范围更大,这种好处是通用性更强
- 子类继承了父类的类型,子类既是 子类类型 也是 父类类型
- 传入类型设置为 父类 可以有很好的通用性
1 | |
要理解什么是多态,我们首先要对数据类型再作一点说明。当我们定义一个class的时候,我们实际上就定义了一种数据类型。我们定义的数据类型和Python自带的数据类型,比如str、list、dict没什么两样:
1 | |
判断一个变量是否是某个类型可以用isinstance()判断:
1 | |
看来a、b、c确实对应着list、Animal、Dog这3种类型。
但是等等,试试:
1 | |
看来c不仅仅是Dog,c还是Animal!
不过仔细想想,这是有道理的,因为Dog是从Animal继承下来的,当我们创建了一个Dog的实例c时,我们认为c的数据类型是Dog没错,但c同时也是Animal也没错,Dog本来就是Animal的一种!
所以,在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行:
1 | |
Dog可以看成Animal,但Animal不可以看成Dog。
要理解多态的好处,我们还需要再编写一个函数,这个函数接受一个Animal类型的变量:
1 | |
当我们传入Animal的实例时,run_twice()就打印出:
1 | |
当我们传入Dog的实例时,run_twice()就打印出:
1 | |
当我们传入Cat的实例时,run_twice()就打印出:
1 | |
看上去没啥意思,但是仔细想想,现在,如果我们再定义一个Tortoise类型,也从Animal派生:
1 | |
当我们调用run_twice()时,传入Tortoise的实例:
1 | |
你会发现,新增一个Animal的子类,不必对run_twice()做任何修改,实际上,任何依赖Animal作为参数的函数或者方法都可以不加修改地正常运行,原因就在于多态。
多态的好处就是,当我们需要传入Dog、Cat、Tortoise……时,我们只需要接收Animal类型就可以了,因为Dog、Cat、Tortoise……都是Animal类型,然后,按照Animal类型进行操作即可。由于Animal类型有run()方法,因此,传入的任意类型,只要是Animal类或者子类,就会自动调用实际类型的run()方法,这就是多态的意思:
对于一个变量,我们只需要知道它是Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
继承还可以一级一级地继承下来,就好比从爷爷到爸爸、再到儿子这样的关系。而任何类,最终都可以追溯到根类object,这些继承关系看上去就像一颗倒着的树。比如如下的继承树:
1 | |
静态语言 vs 动态语言
对于静态语言(例如Java)来说,如果需要传入Animal类型,则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。
对于Python这样的动态语言来说,则不一定需要传入Animal类型。我们只需要保证传入的对象有一个run()方法就可以了:
1 | |
这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
Python的“file-like object“就是一种鸭子类型。对真正的文件对象,它有一个read()方法,返回其内容。但是,许多对象,只要有read()方法,都被视为“file-like object“。许多函数接收的参数就是“file-like object“,你不一定要传入真正的文件对象,完全可以传入任何实现了read()方法的对象。
抽象类
抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化
比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中有抽象方法,该类不能被实例化,只能被继承,且子类必须实现抽象方法。这一点与接口有点类似,但其实是不同的,即将揭晓答案
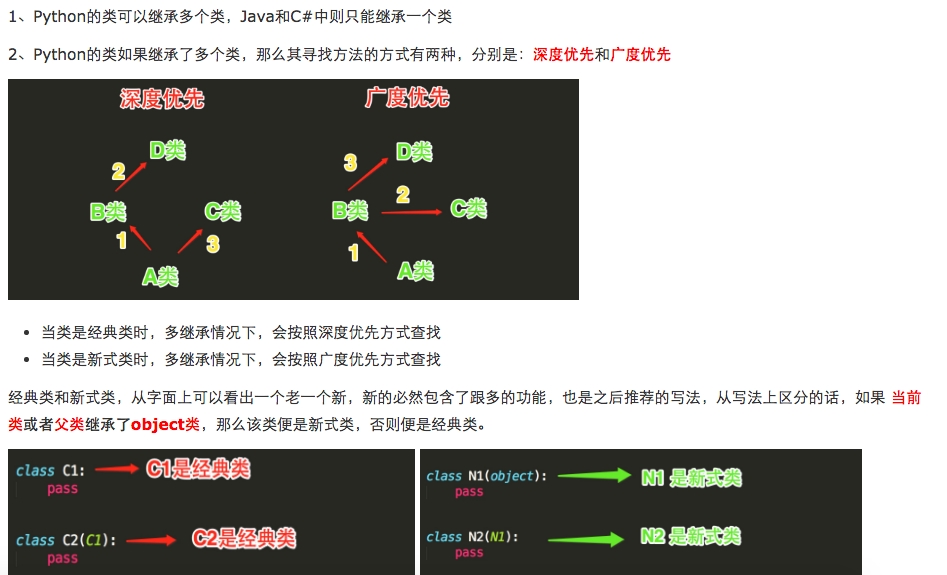
经典类和新式类